이번 글에서는 Cohort분석을 통해서 고객들이 웹사이트/앱에 얼마나 재방문을 하는지 파악하는 방법을 알아보고자 한다. COHORT 분석의 기초 개념부터 시작하여, 실제 어떻게 코드로 구현할 수 있는지, 마지막으로 실무에서는 Retention 인사이트를 어떻게 뽑아낼 수 있는지 알아보겠다.
COHORT 분석의 정의와 활용 방법
- 코호트 분석의 정의
코호트 분석(COHORT Analysis)이란 특정 기간 동안 일정한 기준으로 동일한게 묶을 수 있는 사용자들의 집단을 분석하는 기법이다. 가장 흔하게 쓰이는 방법은 특정 날짜를 기준으로 사용자들을 하나의 집단으로 묶어 이들의 행동을 분석하는 것이다.
- 코호트 분석을 하는 이유
가장 핵심적인 것은 왜 고객들을 하나의 집단으로 묶는가를 아는 것이다. 실무적으로는 고객들의 Exit Rate와 Retention Rate(재방문율 혹은 재구매율)을 파악하여 정기적으로 문제를 진단하고, 해결 전략을 도출하기 위한 대시보드로 많이 활용된다.
또 다른 활용도는 고객집단 별로 고객 생애 가치(LTV, Lifetime Value)를 계산하고, 서비스의 고착도(Stickiness)를 판단할 수 있는 아주 중요한 수단이 된다. 예를 들어 5월 가정의 달 프로모션 때문에 가입한 고객들은 과연 얼마나 서비스에 남아 있고, 총 소비를 얼마나 하는지 궁금할 수도 있다. 이럴 때 코호트 분석을 활용하면, 비즈니스 질문에 가장 최적화된 답을 내놓을 수 있다.
코호트 분석(COHORT Analysis)의 순서와 코드[Python]
Step1. 코호트 분석의 목적 설정하기
다시 한 번 말하지만 코호트 분석은 소비자들을 날짜를 기준으로 동일한 집단으로 묶어주는 분석 기법이다. 가장 중요한 것은 무엇을 보기 위해서 그들을 하나의 집단으로 묶는가를 명확히 인지하고 넘어가야 한다. 이번 분석에서는 2가지 목표를 잡고 코호트 분석을 진행하고자 한다.
목표1. 월별로 소비자들의 재구매율을 판단하여, 2~3달 이내에 가장 많이 이탈한 집단을 발견한다.
목표2. 소비자 집단별로 수익성을 판단하여, 어떤 Group의 재방문 및 재구매율을 촉진시켜야 하는지 선정한다.
Step2. 사전 준비 작업 진행 - 패키지 및 데이터 불러오기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
## 이번 분석에 필요한 패키지 불러오기
import pandas as pd
from pandas import Series
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
## 샘플 데이터 불러오기
df=pd.read_excel('https://github.com/springcoil/marsmodelling/blob/master/relay-foods.xlsx?raw=true',
sheet_name='Purchase Data - Full Study')
df.head()
OrderId OrderDate UserId TotalCharges CommonId PupId PickupDate
262 2009-01-11 47 50.67 TRQKD 2 2009-01-12
278 2009-01-20 47 26.60 4HH2S 3 2009-01-20
294 2009-02-03 47 38.71 3TRDC 2 2009-02-04
301 2009-02-06 47 53.38 NGAZJ 2 2009-02-09
302 2009-02-06 47 14.28 FFYHD 2 2009-02-09
|
cs |
- 기본 데이터 설명
- Order ID: 주문 마다 발생하는 고유의 코드를 의미한다.
- Order Date: 주문이 발생한 날짜를 의미한다.
- User ID: 고객마다 갖고 있는 고유의 아이디이다.
- Total Charge: 주문에서 발생한 총 비용을 의미한다.
- Command ID부터 pickup date는 쓰지 않을 Column 이기에 넘어가도록 한다.
Step3. 분석을 위한 데이터 전처리 작업 거치기
- 전처리 과정1. 필요 없는 데이터 Column삭제하기
- 필요 없는 Column이나 Row를 삭제할 때는 항상 pands.drop 메소드 활용하는 것을 권장한다.
- drop 메소드 기초 파라미터 정리
- DataFrame.drop( 삭제할 데이터, axis = 1이면 column 0이면 row)
- 전처리 과정2. 구매주기를 월별로 계산할 수 있는 날짜 형식 치환하기
- 우리의 관점은 월별 소비자 집단을 규정하는 것이기 때문에 date → Month로 바꿔주는 과정을 진행해야 한다.
- 그래서 각 구매가 이루어진 날짜를 "OrderCycle"이라는 열에 삽입하여 데이터를 준비했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
## 전처리 과정1. 필요 없는 Column들은 Pandas의 Drop Method를 활용
df = df.drop(['CommonId','PupId','PickupDate'],axis=1)
## 전처리 과정2. 우리는 월별 데이터가 목적이기 때문에 데이터 형식을 치환
df['OrderCycle']=df['OrderDate'].dt.strftime('%Y.%m')
## 샘플 데이터 뽑아서 확인해보기
df.sample(3)
Index OrderId OrderDate UserId TotalCharges OrderCycle
341 589 2009-05-15 1023 26.3700 2009.05
2636 2536 2010-01-28 252654 51.9398 2010.01
2617 2396 2010-01-18 247885 39.7000 2010.01
|
cs |
Step4. 코호트 분석에 필요한 변수 생성하기
- 고객별로 첫 구매가 언제 이루어졌는지 파악하기
- Pandas의 Group by 메소드를 이용하면 정말 다양한 데이터 처리가 가능하다.
- min, max, nunique, sum 등 많은 집계함수를 이용하여 원하는 데이터 처리가 가능하니 시간이 될 때 숙지하기 바란다.
- 또한 데이터 형태를 Series로 저장하였는데, 이는 차후 DataFrame과 연결시 Index를 기준으로 데이터 병합하기에 굉장히 용이하기 때문이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
## Group by를 통한 최고 구매일 계산
first_order = df.groupby('UserId').OrderDate.min()
first_order = first_order.dt.strftime('%Y.%m')
first_order.sample(4)
## 데이터 결과 예시
UserId
14056 2009.05
101947 2009.11
50406 2009.08
181222 2009.12
|
cs |
- 고객의 첫 구매 데이터를 DataFrame에 붙이기
- Pands와 Series 데이터를 병합할 때 Tip은 Index를 기준으로 병합하면 굉장히 편하다는 것이다.
- First Order는 정확히 말해서, Index가 있는 Series 데이터이다. 이때 그냥 DataFrame에 붙이게 되면 에러가 나거나 의도하지 않은 방향으로 데이터가 무작위로 형성될 위험이 있다.
- 이때 DataFrame의 index를 User ID로 설정한 뒤 지정을 하면, 자동으로 Index 기준으로 데이터 병합을 할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
## Data Frame의 Index를 User Id로 일시적으로 전환
df = df.set_index('UserId')
## 데이터 First 데이터는 Series + DF는 pandas이기에 Index 기준 자동 병합가능
df['FirstOrder'] = first_order
## Index의 정상화
df.reset_index(inplace = True)
df.sample(3)
UserId OrderId OrderDate TotalCharges OrderCycle FirstOrder
2930 331 2009-02-21 69.8400 2009.02 2009.02
20805 778 2009-06-24 50.9800 2009.06 2009.06
17533 1979 2009-12-07 74.2625 2009.12 2009.05
|
cs |
여기까지 진행하면 Raw Data에서 필요한 모든 준비는 끝났다고 볼 수 있다. 이제부터는 코호트 분석에 맞는 데이터 형태로 치환을 하여 본격적인 분석을 진행해야 한다.
Step5. 월별로 구매 고객 데이터 치환하여 보기
- 월별로 구매 고객을 볼 때 총 2가지 데이터를 계산해야 한다.
- 첫 번째. 주기별 구매한 User의 수 계산
- 두 번재. 주기별 구매한 금액의 계산
- 이 두가지 데이터를 합칠 때는 Pandas의 merge라는 메소드를 활용하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
## 주기별 구매 User 계산
co1 = df.groupby(['FirstOrder', 'OrderCycle']).UserId.nunique()
co1 = co1.reset_index()
co1.rename({'UserId': 'TotalUsers'}, axis = 1, inplace = True)
## 주기별 구매 금액 계산
co2 = df.groupby(['FirstOrder', 'OrderCycle']).TotalCharges.sum()
co2 = co2.reset_index()
co2.rename({'TotalCharges': 'PurchaseAmnt'}, axis = 1, inplace = True)
## 데이터의 병합
co = co1.merge(co2, on = ['FirstOrder', 'OrderCycle'])
co.head()
FirstOrder OrderCycle TotalUsers PurchaseAmnt
2009-01 2009-01 22 1850.255
2009-01 2009-02 8 1351.065
2009-01 2009-03 10 1357.360
2009-01 2009-04 9 1604.500
2009-01 2009-05 10 1575.625
|
cs |
Step6. 코호트 기간 기준 계산 및 데이터 형태 최종 완성
- 코호트 기간 기준 계산 방법
이제부터 코호트의 기준 기간을 계산해야 한다. 위의 예시를 통해서 설명하면 이해가 훨씬 빠를 것이다. 첫 번째 줄의 경우 First Order은 2009-01이고, Order Cycle 또한 2009-01이다. 이 두 기간의 차이를 월로 계산하면 0이된다. 그 다음 줄의 예시를 보면 전자는 동일하게 2009-01이고, 후자는 2009-02이기에 둘 간의 월 차이는 1이된다. 이렇게 모든 Row에서 월차수를 구하는 코드를 for 반복문을 통해서 계산하면 아래와 같이 계산할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
from ipypb import ipb
temp = []
for i in ipb(range(co.shape[0])):
f_first_order = pd.to_datetime(co.FirstOrder[i]).to_period('M')
f_order_cycle = pd.to_datetime(co.OrderCycle[i]).to_period('M')
month_diff = (f_order_cycle - f_first_order).n
temp.append(month_diff)
co['CohortPeriod'] = temp
|
cs |
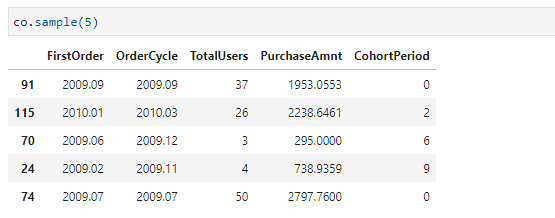
- 코호드 데이터 형태 최종 완성 - Pandas Unstack 활용
- Pandas stack & unstack 메소드 설명
- pd.stack은 Column에 있는 값들을 Index로 변환해주는 명령어이다.
- pd.unstack은 index에 있는 값들을 column으로 변환해주는 명령어이다.
- co.TotalUsers.unstack(1)을 설명하면 아래와 같다.
: "co라는 데이터에서 Total Users들 값을 기준으로 계산할 거야. 근데 인덱스 중 2번재 인덱스(Cohort Period)를 Column으로 이동 시켜줘."라고 명령하게 된다. 그러면 아래의 사진의 예시처럼 두 번째 인덱스가 Column으로 이동하게 된다. 이 형태가 최종적으로 데이터 분석의 마무리 형태이니, 이 부분을 아주 잘 이해하길 바란다.
- co.TotalUsers.unstack(1)을 설명하면 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
|
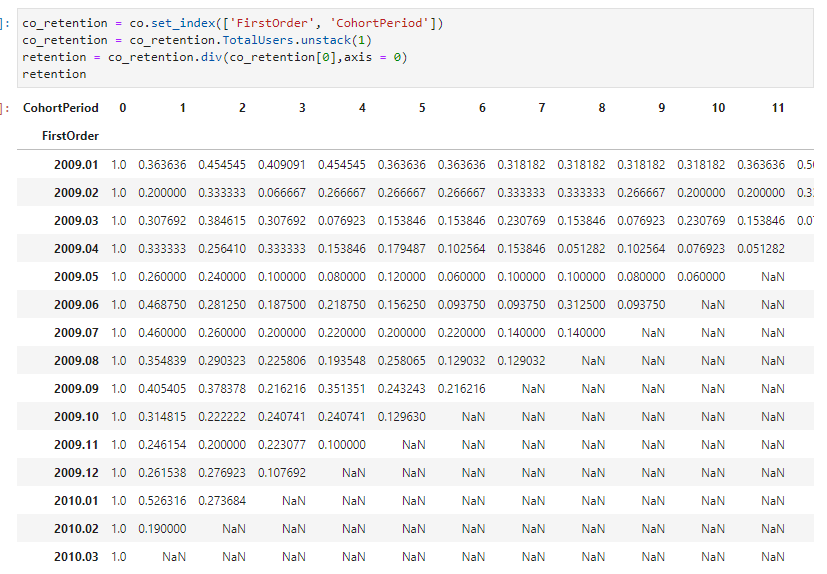
## 첫 번째. 재방문율 계산을 위한 Pandas Unstack 활용
co_retention = co.set_index(['FirstOrder', 'CohortPeriod'])
co_retention = co_retention.TotalUsers.unstack(1)
retention = co_retention.div(co_retention[0],axis = 0)
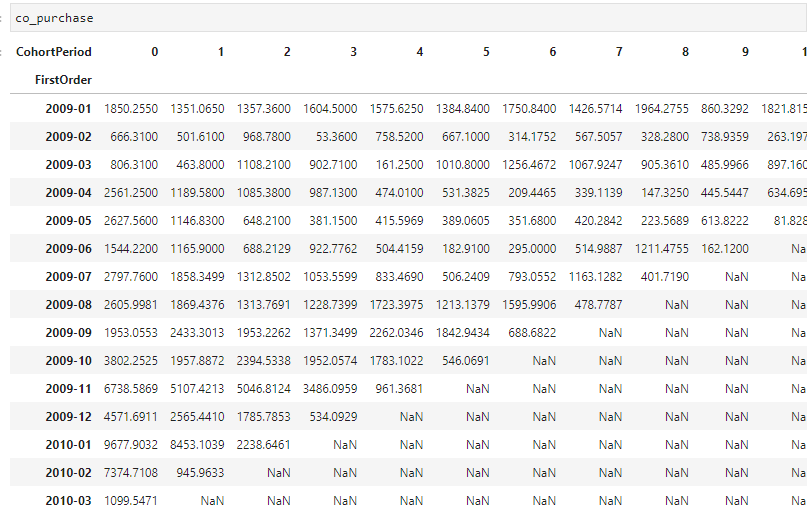
## 두 번째. 구매 규모 형태 치환을 위한 Pandas Unstack 활용
co_purchase = co.set_index(['FirstOrder', 'CohortPeriod'])
co_purchase = co_purchase.PurchaseAmnt.unstack(1)
|
cs |
 |
 |
Step7. 코호트 분석 시각화 - Cohort Analysis Visualization
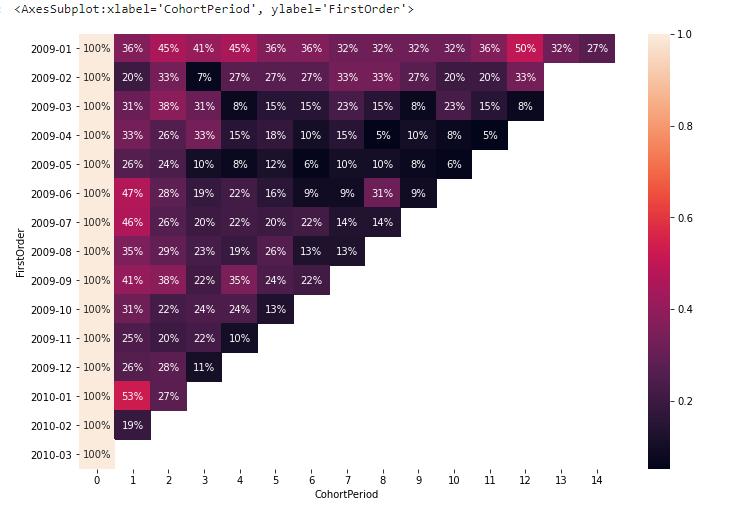
코호트 분석 시각화시 활용하면 좋은 패키지는 Seaborn 중 heatmap이 있다. 이 패키지를 활용하면 누구나 쉽게 아주 효과적인 시각화를 만들어 볼 수 있으니, 공부할 때 참고하길 바란다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import matplotlib.pyplot as plt
import seaborn as sns
## 재방문율 시각화 진행
plt.rcParams['figure.figsize'] = (12, 8)
sns.heatmap(retention, annot = True, fmt = '.0%')
## 구매 규모 시각화
plt.rcParams['figure.figsize'] = (20, 12)
sns.heatmap(co_purchase, annot = True
# , fmt = '.0%'
)
plt.yticks(rotation = 360);
|
cs |
 |
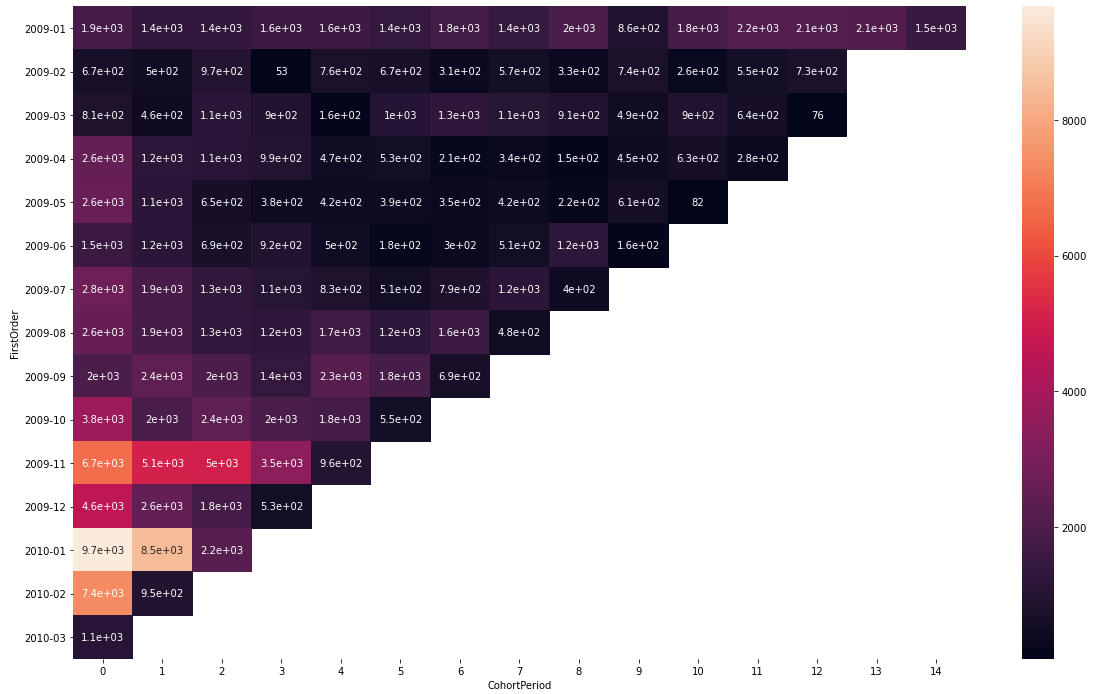 |
여기까지 진행하면 코호트 분석에 관련한 코드와 이론은 모두 완성한 것이다.
코호트 분석(COHORT Analysis) 예시 및 해석 가이드
우리가 초기에 설정한 2가지 목표를 잡고 데이터 해석을 진행해보도록 하겠다. 모든 데이터 분석이 그렇지만 단순히 데이터를 추출하고 보는 것보다는 데이터가 어떤 의미를 지니고, 어떤 insight를 뽑아내야하는지 데이터 문해력이 더욱 중요하기 때문에 항상 이 연습을 진행해야 한다.
- 목표1. 월별 소비자 집단 중 이탈이 가장 많은 집단 파악
- 코호트 기간을 1로 고정해 놓고 봤을 때 가장 이탈률이 높은 집단 순위를 산출해보겠다.
- 2010년 2월 - 재구매율 19%
- 2009년 2월 - 재구매율 20%
- 2009년 11월 - 재구매율 25%
- 2009년 5월 - 재구매율 26%
- 2009년 12월 - 재구매율 26%
- 코호트 기간을 1로 고정해 놓고 봤을 때 가장 이탈률이 높은 집단 순위를 산출해보겠다.
- 목표2. 수익성 기반 Retention을 재고해야 할 집단 선정
- 2010년 1월 - 약 9천 달러
- 2010년 2월 - 약 7천 달러
- 2009년 11월 - 약 6천 7백 달러
위의 두 가지 결과를 봤을 때 우선 필자의 눈에 들어오는 것은 2010년 2월달 구매자들이다. 구매 규모만 놓고 보면, 2순위로 기록될 만큼 굉장히 큰 구매력이 있는 집단이다. 그러나 재방문율을 놓고 봤을 때 이탈이 가장 많이 된 집단이기도 하다. 따라서 현재 2010년 2월에 굉장히 매출이 잘 나왔다하더라도, 이 고객들이 서비스에 남아있지 않고 이탈하여 장기적인 수익을 놓치고 있는 상황이라는 것을 유추해볼 수 있다.
이런 식으로 항상 데이터 문해력을 높이는 연습을 같이 해보길 권장한다.
'통계학 기초' 카테고리의 다른 글
| [Python]이원분산분석(Two-way ANOVA) 코드부터 결과 해석 가이드 (1) | 2022.09.15 |
|---|---|
| [Python] 카이제곱 독립성 검정을 활용한 데이터 분석(feat. A/B Test까지) (0) | 2022.08.30 |
| [Python]베이지안 A/B Test로 기대수익과 기대손실 계산하는 방법 (0) | 2022.08.11 |
| [Python] 선형회귀분석을 이론, 결과해석, 그리고 코드까지 (Linear Regression Model) (0) | 2022.07.20 |
| [Python] One way ANOVA 분석하기 - 이론부터 코드까지 한 번에 (1) | 2022.06.22 |



