카이제곱(chi-square) 독립성 검정은 두 변수 간 상호 영향도를 판단할 때 사용하는 대표적인 통계모델이다. 오늘은 이 모델의 개념과 수식부터 시작해서 예제를 통해 이해해보도록 하겠다. 또한 실제 A/B Test에서는 카이제곱 모델을 어떻게 활용하는지 Python을 통해서 구현해보도록 하겠다.
글의 목차
1. 카이제곱 독립성 검정의 개념
2. 카이제곱 독립성 검정의 수식
3. A/B Test에서 활용하는 카이제곱 독립성 검정
카이제곱 독립성검정의 개념
카이제곱 독립성 검정의 목표는 "내가 설정한 독립변수(원인)가 종속변수(결과)에 정말 영향을 미치는지 아니면 독립적인지"하기 위해서 하는 작업이다. 인과관계를 증명할 때 다양한 모델이 있지만, 카이제곱 검정을 반드시 써야만 할 때가 있다. 그렇다면 어떤 상황에서 이 모델을 활용하는지 아주 간단하게 정리를 해보도록 한다.
- 카이제곱 독립성 검정의 목적
- 독립변수와 종속변수 간의 인과관계를 확인하기 위해서 확인하는 것
- 변수 간 움직임이 독립적인지 확인하기 위해서 하는 것이다.
- 카이제곱 독립성 검정의 가설 (귀무가설 & 대립가설)
- 귀무가설(H0): 독립변수는 종속변수와 상호 독립적이다.
- 대립가설(H1): 독립변수는 종속변수와 독립적이지 않다.
- 따라서 우리는 검정 통계량(P-value)가 0.05 이하로 나와야 원하는 결과를 확인할 수 있는 것이다.
- 카이제곱 독립성 검정 해석 방법은 대립가설이 채택되면, "독립변수가 달라지면, 종속변수도 달라지니, 우리가 설정한 요인이 확실히 영향을 미치고 있구나"라는 것을 확인할 수 있다.
- 카이제곱 독립성 검정 변수의 척도는 명목척도를 사용해야 한다.
- 독립변수: 원인에 해당하는 변수는 명목척도가 들어와야한다.
- 종속변수: 결과에 해당하는 변수도 명목척도가 들어와야 한다.
- 명목척도란 숫자에 큰 의미가 없고, 단순하게 종류가 다르다는 것을 나타내는 척도이다.
- 예를 들면, 학급은 1반,2반,3반 등 숫자는 있지만, 다름을 나타낼뿐 우열이나 숫자로서 의미는 없다.
- 카이제곱 독립성 검정의 중요 통계량
- 검정 통계량은 카이제곱 계수(χ^2)이고, 이 숫자가 유의미한지 검증하는 것이 핵심적이다.
- 모델에서 카이제곱분포표, 자유도, 실제값, 그리고 기대값에 대한 것은 아래의 영역에서 상세하게 설명하도록 하겠다.
카이제곱 독립성 검정의 수식
- 수식으로 이해하는 카이제곱 검정
- 카이제곱 계수 정의: χ^2 = Σ ( E - O )^2 / E
- E(기대값, Expectation): 만약 두 변수가 독립이라는 가정하에 기대하는 값이다. 예를 들어, P(A)와 P(B)가 발생할 확률이 독립적이라면, 우리는 P(A ∩ B) = P(A) * P(B)로 계산할 수 있다.
- O(관측값, Observation): 실제 데이터에서 관측된 숫자
- 카이제곱 자유도 정의: ( Row - 1 ) * ( Column - 1 )
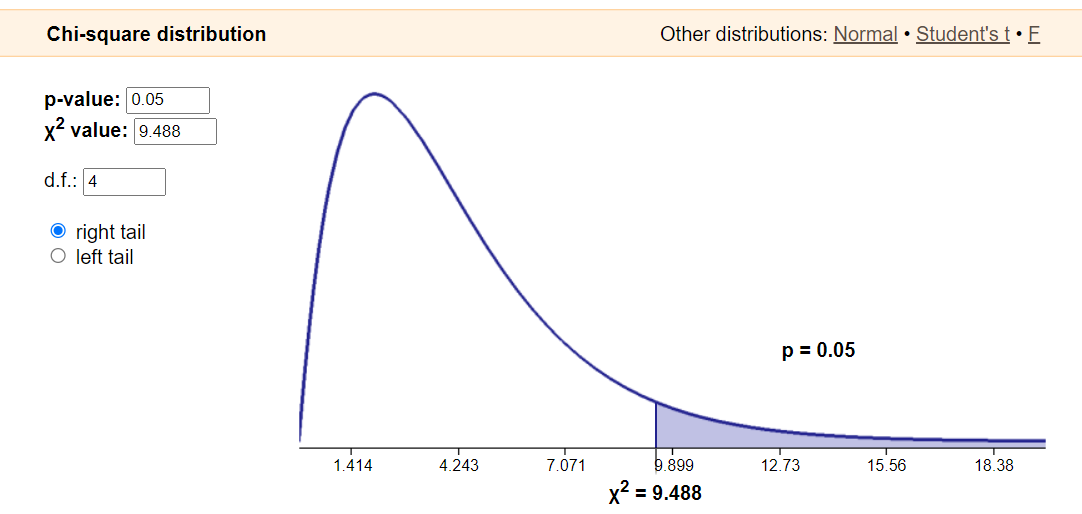
- 카이제곱 분포표
- 일반 정규 분포에도 표준 정규 분포표가 있듯이, 카이제곱 모델에서도 공통으로 사용할 수 있는 카이제곱 분포표가 있다.
- 이 분포는 위에서 계산한 카이제곱 계수, 자유도, 그리고 유의수준을 파라미터로 받아 결정되는 분포이다.
- 아래의 사이트로 이동하면, 실제 카이제곱 계수와 자유도에 따라 어떤 분포가 형성되는지 알 수 있기 때문에 공부 삼아 들어가보는 것을 권장한다.
- 카이제곱 계수 정의: χ^2 = Σ ( E - O )^2 / E
카이제곱 검정의 예시를 통한 이해와 결과 해석

- 카이제곱 독립성 검정의 계산방법 예시
- 기대값 계산 방법 안내 - 두 변수가 독립이라는 가정하에
- ⓐ의 계산 방식 안내 = P(3명이하 ∩ SUV 소유) * 전체 샘플 수 = P(3명 이하) * P(SUV 소유) * 전체 샘플 수
= 0.5 * 0.4 * 100 = 20명
- ⓐ의 계산 방식 안내 = P(3명이하 ∩ SUV 소유) * 전체 샘플 수 = P(3명 이하) * P(SUV 소유) * 전체 샘플 수
- 카이제곱 계수 산출 방법 안내 - ( E - O )^2 / E
- ⓐ의 카이제곱 계수 = ( 20 - 5 ) ^ 2 / 20 = 11.25
- 카이제곱 검정 자유도 계산 방법
- ( Row - 1 ) * ( Column - 1 ) = (3 - 1) * (2 - 1) = 2
- 기대값 계산 방법 안내 - 두 변수가 독립이라는 가정하에
위 표 중에서 하나의 칸을 예시로 기대값과 카이제곱 계수를 계산하는 방법을 알아봤다. 동일한 논리로 총 6개 칸의 카이제곱 계수를 산출할 수 있고, 이게 최종적인 모델의 계수가 되는 것이다. 유의도를 1%로 놓고, 계산한 결과는 이렇다. 최종 검정 카이제곱 계수는 42.9가 되고, 카이제곱 검정분포표에 따라 유의 수준이 1%이면 임계점이 9.21로 계산된다. 이때 42.9 > 9.21이기 때문에 귀무가설을 기각하고, 대립가설을 채택할 수 있다. 위의 예시에 적용한다면, 가족 구성원 수는 SUV 소유 여부에 충분히 영향을 주는 변수라고 해석할 수 있는 것이다.
A/B Test에서 활용하는 카이제곱 검정
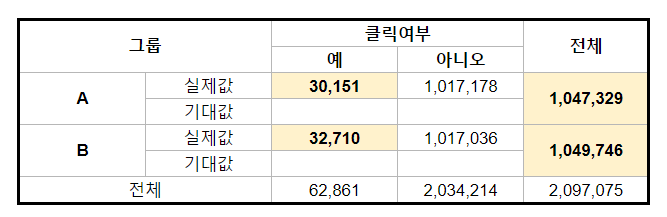
우리는 Python에서 Stats 패키지를 활용하여 실제 모델을 구현해보는 연습을 할 것이다. 이때 A/B Test 환경에서 필요한 파라미터는 각 그룹별 클릭 수와 전체 사용자 수이다. 이렇게 되면 총 4개의 파라미터를 준비해야 하고, 위 표에서 색칠한 영역의 숫자가 되는 것이다.
- 기초 데이터 및 Stats 패키지 준비 과정
- Python에서 카이제곱 검정을 위해서 필요한 패키지는 stats의 chi2_contingency 패키지이다.
- 데이터를 받을 때는 input 함수를 써서 받았고, 기본적으로 input을 string 형태로 자료를 받기 때문에 밑의 코드에서 숫자로 바꿔주는 작업을 진행하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from scipy.stats import chi2_contingency
import pandas as pd
import numpy as np
data = input('[a_click, total_a, b_click, total_b]')
temp = data.replace(' ', '').split(',')
clean_data = [ int(temp[i]) for i in range(len(temp)) ]
l_result = clean_data.copy()
|
cs |
- Python을 활용한 카이제곱 독립성 검정 코드
- Part1은 기초 데이터를 받은 것을 클릭한 것과 클리하지 않은 수를 계산하는 과정이다.
- Part2는 위의 그림에서 형성된 표를 직접 크리는 과정을 코드로 구현한 것이다.
- Part3은 카이제곱 독립성 검정 모델을 선언하고, 결과 값으로 받을 검정 계수값, 유의 결과, 자유도, 그리고 기대값을 반환하는 코드를 구성하였다. 이제 chi2라는 값에 click과 no click이라는 숫자가 들어가게 되면 모델에 맞는 결과를 반환할 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
## Part1. Chi-square Test Report
click = [l_result[0], l_result[2]] # A와 B의 클릭한 유저 수
no_click = [l_result[1] - l_result[0], l_result[3] - l_result[2]] # A와 B의 클릭 안 한 유저 수
## Part2. Contingency Table & Chi-squaure Model
## 기초 테이블 형성
cont_table = pd.DataFrame([click, no_click], columns=['A', 'B'], index=['click', 'no_click'])
## Part3. 카이제곱 독립성 검정 모델 선언
chi2, p_val, d_f, expected = chi2_contingency([click, no_click])
## 기대값 표 형성
ex = pd.DataFrame(expected, columns = ['A', 'B'], index = ['click', 'no_click'])
print( ' '
, '[Chi-square Analysis Result Report]'
, 'Chi-square: {}'.format(round(chi2, 2))
, 'P-value: {}'.format(round(p_val, 2))
, '--------------------------'
, 'Expected Values'
, ex
, '--------------------------'
, 'Observed Values'
, cont_table
, '=========================='
, ' '
, sep = '\n'
)
|
cs |
- 카이제곱 독립성 검정을 통한 A/B Test 결과 해석
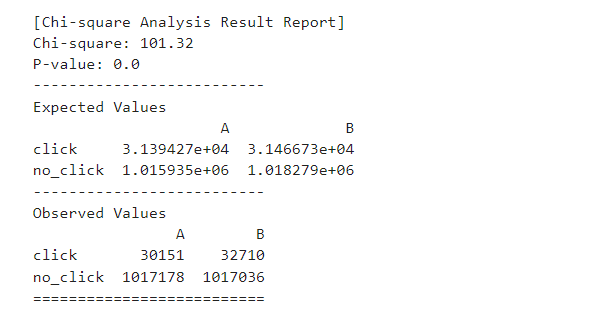
우선 P-value가 0.0으로 굉장히 유의하기 때문에 대립가설을 채택해야 한다. A/B Test의 대립가설은 "자극물에 따라서 클릭율은 독립적이지 않고, 영향을 받는다"가 된다. 따라서 이번 결과 같은 경우 카이제곱 계수 101.32는 굉장히 유의하게 나왔기 때문에 클릭율 높은 변수를 채택해야 할 것이다. 이 경우 실제 값을 기반으로 했을 때 A의 CTR은 2.88%이고, B의 CTR은 3.12%이기 때문에 최종적으로 선택해야 하는 것은 B가 되겠다.
'통계학 기초' 카테고리의 다른 글
| [Python]독립표본(Independent Samples) T-Test를 활용한 A/B Test 검증(코드부터 결과 해석까지 한 번에) (1) | 2023.10.04 |
|---|---|
| [Python]이원분산분석(Two-way ANOVA) 코드부터 결과 해석 가이드 (1) | 2022.09.15 |
| [Python] COHORT 분석 개념부터 실전 코드까지 (feat. 분석 예제 포함) (0) | 2022.08.18 |
| [Python]베이지안 A/B Test로 기대수익과 기대손실 계산하는 방법 (0) | 2022.08.11 |
| [Python] 선형회귀분석을 이론, 결과해석, 그리고 코드까지 (Linear Regression Model) (0) | 2022.07.20 |



