통계학 모델 중에서 가장 기초이자 반드시 알아야 할 선형회귀분석(Linear Regression Model)을 소개할 것이다. 이 통계 모형을 처음 듣는 사람에게 설명한다는 관점으로 회귀분석이론부터 시작하여 회귀분석의 목적, 수식으로 이해하는 회귀모형, 회귀분석의 목적 그리고 회귀분석 결과 해석하는 가이드를 설명할 것이다. 이 모든 과정을 Python으로 구현해봄으로써 실무에서 어떻게 사용할 수 있을지까지 힌트를 남길 것이다.
[ 글의 목차 ]
1. 회귀분석의 기초
2. 선형회귀분석의 목적
3. Linear Regression Model의 수식
4. 선형회귀분석의 해석 방법
5. 코드로 Linear Regression Model 구현해보기
1. 회귀분석의 기초
회귀분석을 가장 쉽게 말하자면, 결과를 일으키는 원인을 찾아가는 과정이다. 통계적인 관점으로 보면 종속변수를 설명하기 위해서, 체계적 변수와 비체계적 변수로 설명하는 수식이다. 각각의 변수를 구조적으로 이해하면 아래의 그림과 같고, 각 변수에 대한 설명을 해보도록 하겠다.

- 회귀분석과 관련된 변수 설명
- 종속변수: 실험에서는 결과에 해당하는 값이고, 1차 방정식으로 간단하게 이해하면 y에 해당한다.
- 체계적 변수: 이는 사람이 설정, 통제, 혹은 조절할 수 있는 영역으로 연구자들이 인위적으로 변화를 만들 수 있는 부분을 의미한다.
- 독립변수: 원인에 해당하는 개념이고, 논문이나 실험 환경에서는 자극이나 처치라고도 쓴다.
- 통제변수: 인위적으로 조작할 수 있지만, 연구에서 핵심적인 관점을 두지 않는 대상
- 실험 연구 환경: 무작위 배분과 같이 독립변수 이외에 종속변수에 영향을 주는 대상들을 통제하는 것을 의미한다.
- 예측(이해) 분야: 모델의 타당성(Validity)를 높이는 역할을 수행한다. 왜냐하면 모형 전체가 통제변수를 Control 했을 때 유사한 결과값을 낼 수 있다면 모델이 다른 환경에서도 쓰일 수 있다는 의미로 해석될 수 있기 때문이다 .
- 비체계적 변수: 이는 모델에서 통계 오차에 해당하는 개념이고, 보통 정규분포가 나오는 경우가 가장 이상적이다. 왜냐하면 오차 관측치가 서로 독립적이라면, 독립변수와 통제변수와도 독립적임을 가정할 수 있기 때문이다. 이는 최대 엔트로피 분포로 이해할 수 있는데, 가장 편향적이지 않은 분포를 가정한다고 이해하면 된다.
2. 선형회귀분석의 목적
(1) 데이터의 이해(Understanding)
회귀분석의 기본적인 목적은 X(독립변수)를 갖고 Y(종속변수)의 변화를 이해하는 것이 핵심이다. 이러한 관점에서 회귀분석은 과거 현상이 어떤 원인 때문에 발생했는지 밝혀내고 이해하는데 사용될 수 있다. 예를 들면, "기본금리 상승과 이자율 상승은 어떤 관계를 갖고 있는가"와 같은 질문에 대한 답을 찾는데 회귀분석이 사용될 수 있다. 그래서 이러한 목적으로 데이터를 볼 때는 모델이 갖고 있는 설명력(R^2)이 중요할 것이다.
(2) 예측(Prediction)
Regression은 대표적으로 머신러닝 분야 중 Supervised Learning에서 사용하는 모델 중 하나이다. 이 분야의 핵심은 과거의 데이터를 기반으로 모델을 형성하여, 미래의 값을 예측하는데 사용하는 것이다. 예를 들면, "기본금리가 1%p 상승하면 코스피는 얼마나 증가 혹은 감소를 할지 예측"하는데 사용하는 것이다. 만약 Regression을 이러한 목적으로 사용하게 되면 가장 중요한 지표는 F1-Score이 될 것이다 .
(3) 인과관계 증명 (Cause & Effect)
통계 해석학에서 가장 중요한 목적 중에 하나인 인과관계를 측정하고, 그것이 정말 맞는지 증명하는데 회귀분석이 활용된다. 조금 더 세부적으로 말하면 인과 관계를 측정하고 추적하는 기능을 수행할 수 있다. 인과관계 측정이라고 하면, 다른 요인을 통제했을 때, 원하는 효과가 다시 반복적으로 나타나는가를 확인하는 것이다. 추적(증명)은 종속변수(Y)의 변화를 독립변수(x)의 변인에 귀속시킬 수 있는지 검증하는 것이다.
따라서 자기가 지금 어떠한 목적으로 데이터를 바라보는지에 따라 동일한 회귀분석이어도 사용할 수 있는 방법은 다양하게 있다.
3. Linear Regression Model의 수식
사실 회귀분석에는 정말 다양한 종류가 존재하지만, 오늘은 가장 기본적인 선형회귀분석에 한하여 깊게 알아보고자 한다.
- 수식으로 이해하는 선형 회귀분석
- y는 종속변수로 Numeric Scale을 갖고 있어야 한다.
- x는 독립변수로 이 또한 Numeric Scale을 갖고 있어야 한다.
- 베타는 X의 계수로 모델에서 찾고자 하는 핵심 값 중에 하나이다.
- 가장 쉽게 말하면, X가 Y에게 얼마나 큰 영향력을 주는지 알아보는 것이기 때문이다.
- e(엡실론)은 통계 오차로 비체계적 변수에 해당 하는 부분이다.
- 이 오차는 정규분포를 가정하고 있고, 그 이유는 위에서 설명했듯이 최대 엔트로피 분포로 이해할 수 있는데, 가장 편향적이지 않은 분포를 가정한다.
- 그래야 독립변수가 외생변수의 영향에 관계없이 독립적이고 일관적으로 종속변수에 영향을 주는 것이 입증되기 때문이다.
4. 선형회귀분석의 해석 방법 - SDEM 방법

- 선형회귀분석 결과 해석 순서 안내
- Step1. 유의성 검증 - Significance
- 계산한 X의 계수가 실제로 일반화할 수 있는 수치인지 확인하는 과정
- 계수의 p-value가 유의한지 검증하는 것으로 진행
- 사회과학에서는 0.05보다 작으면 계수는 유의한 것으로 해석
- Step2. 방향성 확인 - Direction
- 내가 세운 가설대로 계수의 방향성이 나오는지 확인하는 과정
- 예를 들어 +라고 가설을 세웠는데, 반대의 경우가 나오는지 확인하는 것
- Step3. 효과의 크기 - Effect Size
- 계수 자체의 절대값을 측정하는 것
- 유의하더라도 만약 그 효과 크기가 너무나도 작다면, 실험 결과를 반영하지 않을 수도 있다.
- 예를 들어, A버튼보다 B클릭이 전환율이 높은데, 0.000001%p 높다고 하자. 그런데 A버튼 → B버튼 개발하는데 1억이 들어간다면 결과를 있는 그대로 수용하기 힘들 수도 있다.
- Step4. 모델 적합성 - Model Fitting
- 개념: 통계 모델이 "데이터셋을 전체적으로 얼마나 잘 설명했는가"를 나타내는 것이 모델 적합도이다. 쉽게 말해서 주어진 데이터셋을 모델이 오차범위 내에서 설명을 했다면 적합한 모델이라고 판단하는 것이다.
그러나 데이터셋의 크기와 모델 복합도에 따라서 모델 적합도를 판단하는 것은 생각보다 쉽지만은 않은 일이다. 이 주제만 가지고도 한 포스팅이 나올 수 있는 분야라 여기서는 개념만 이해하고 넘어가도록 한다. - Under-fitting
: 아주 쉽게 말해서 모델이 주어진 데이터셋을 아주 적게 설명하고, 오히려 설명하지 못한 데이터들이 많을 때 우리는 under-fitting이 되었다고 말한다. 이런 현상을 주로 데이터셋이 너무 방대하고, 모델이 너무 단순할 때 나타날 수 있는 현상이다. - Over-fitting
: 오버피팅은 반대로 주어진 데이터셋은 잘 설명했는데, 너무 잘 설명한 나머지 일반화할 수 없는 상태이다. 다른 말로 이 데이터셋만 잘 설명하지, 다른 데이터셋에는 이 모델을 적용할 수 없는 상태를 의미한다.
- 개념: 통계 모델이 "데이터셋을 전체적으로 얼마나 잘 설명했는가"를 나타내는 것이 모델 적합도이다. 쉽게 말해서 주어진 데이터셋을 모델이 오차범위 내에서 설명을 했다면 적합한 모델이라고 판단하는 것이다.
- Step1. 유의성 검증 - Significance
5. 코드로 Linear Regression Model 구현해보기
(1) 데이터셋 기본 설명
- 데이터셋 출처: Kaggle House Prices - Advanced Regression Techniques
- 중요 Column 및 변수 설명
- year_built: 건물이 지어진 연도 - 종속변수
- sale_price: 부동산 판매 가격 - 독립변수
해당 데이터셋에서는 정말 다양한 column들이 있기 때문에 전부 다 파악하는 것은 이번 포스팅 목적에 어긋난다. 따라서 회귀분석을 이해하기 위해서 중요한 변수 2개만 설정하여 회귀분석 실습에 집중하려고 한다.
(2) 데이터 분석 진행
- 기초 데이터셋 준비
|
1
2
3
4
5
6
7
8
9
10
11
|
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LinearRegression
## 데이터셋 불러오기 & 기초 전처리 r1 = pd.read_csv('train.csv')
r1.columns = [ r1.columns[i].lower() for i in ipb(range(len(r1.columns))) ]
t1 = r1.query('yearbuilt >= 1980').reset_index(drop = True)
|
cs |
- 데이터 분석 목적1 - 이해 & 인과관계 관측을 위한 데이터 분석 (통계 해석학)
- 회귀분석 결과를 해석하는 방법은 위에서 언급한 SDEM 방식으로 실습해보고자 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import statsmodels.api as sm
#define response variable
y = t1.saleprice
#define predictor variables
x = t1.yearbuilt
#add constant to predictor variables
x = sm.add_constant(x)
#fit linear regression model
model = sm.OLS(y, x).fit()
#view model summary
print(model.summary())
|
cs |
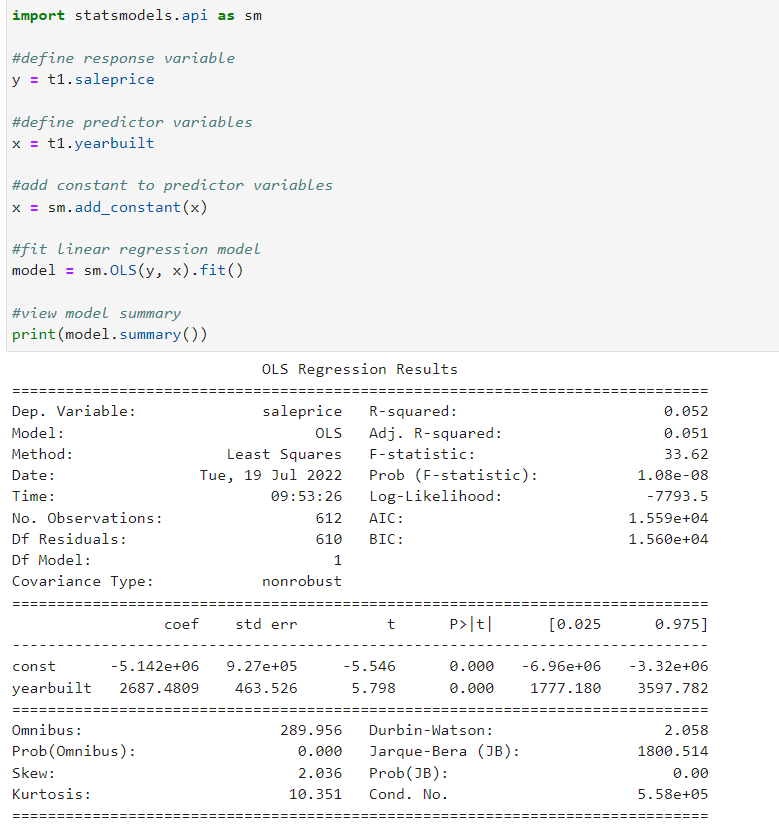 |
1. Significant(유의성 확인) - yearbuilt 변수의 p-value는 0에 수렴하기 때문에 유의한 것으로 나타났다. - 따라서 건축연도는 확실히 부동산 판매가격에 영향을 준다고 볼 수 있다. 2. Direction(방향성 확인) - coef(계수)의 방향성은 양(+)이 방향성을 띈다. - 건축 연도가 최신일 수록 부동산 판매가격에 긍정적인 영향을 준다고 볼 수 있다. 3. Effect Size(효과 크기 측정) - 건축연도가 한 단위(1년) 변할 때 부동산 판매가격은 약 2,687 오르는 것을 확인할 수 있다. 4. Model Fit(모델 적합성 확인) - R제곱과 수정 R제곱 수치가 0.051 ~ 0.052로 나타났다. - 전체 데이터셋 중 약 5.1% ~ 5.2% 밖에 설명하지 못 했다. - 따라서 모델 전체는 과소적합으로 부동산 가격에 영향을 주는 변수가 더 있을 것임을 강하게 암시하고 있다. |
회귀분석 결과는 SDEM 방식으로 이렇게 해석할 수 있고, 그때 봐야할 지표들은 p-value, effect size, coefficient, 그리고 R제곱 수치를 확인해야 한다. 각 수치들을 해석하는 구체적인 방법은 모델마다 다르니 자신의 데이터셋이 어떤 주제를 담고 있는지에 따라 유동적인 해석이 필요하다.
- 데이터 분석 목적2 - 예측을 위한 데이터 분석 (Machine Leanring의 예측)
사실 Python에서 분석 실시하는 코드는 굉장히 쉬운 편이다. 만약 아래의 코드가 이해가 되지 않는다면, 기초 통계 및 Python 기초 문법을 더 공부하는 것을 권장한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
## 변수의 선언
x = t1.yearbuilt
y = t1.saleprice
## 모델의 선언
linear_regression = LinearRegression()
## 모델-데이터셋의 학습 진행
linear_regression.fit(x.values.reshape(-1,1), y)
## 예측 실행
print( '2010년 건축 부동산 예측 가격:{}'.format(linear_regression.predict([[2010]])[0])
, 'X변수 계수: {}'.format(linear_regression.coef_[0])
, sep = '\n')
|
cs |

회귀분석 실시 결과 기울기(계수)는 2687이다. 쉽게 말해서 건축연도가 한 단위(1년) 커질 때마다 부동산 가격은 2,687만큼 커진다는 뜻이다. 2010년도 건축물의 예측 가격은 259,896으로 예측이 되었다.
원래 Machine Learning에서 성과평가를 하기 위해서는 F1-Score, Prediction, Recall 등의 지표를 살펴봐야 하지만, 여기서 다루기에는 포스팅 내용이 너무 길어지기 때문에 다른 포스팅에서 다루려고 한다. 또한 실무적으로 단순 회귀분석은 모델링에 사용하지 않기 때문에 여기서 다루지 않도록 한다.
여기까지 내용을 알고 있다면 선형회귀분석에 대해서 기본적인 지식은 알고 있다고 할 수 있다.
'통계학 기초' 카테고리의 다른 글
| [Python] COHORT 분석 개념부터 실전 코드까지 (feat. 분석 예제 포함) (0) | 2022.08.18 |
|---|---|
| [Python]베이지안 A/B Test로 기대수익과 기대손실 계산하는 방법 (0) | 2022.08.11 |
| [Python] One way ANOVA 분석하기 - 이론부터 코드까지 한 번에 (1) | 2022.06.22 |
| 베이지안 기초4. 실전 A/B Test 코드 구현하기[Python] (0) | 2022.06.07 |
| 베이지안 기초3. 베이지안을 활용한 A/B Test 예시[Python] (0) | 2022.04.26 |



