이전 포스팅에서는 와인 품질 예측을 위해서 기본적으로 어떻게 모델을 적용해서 Classification을 하는지 알아봤다. 이번에는 각 모델 안에서 최적의 결과를 찾을 수 있는 Grid Search를 소개해보고자 한다. 이 과정은 Hypter Paramter를 탐색하는 과정으로 Machine Learning을 공부하는 사람들에게 필수적인 기능이기도 하다.
1. 기초 데이터 준비
우리가 사용할 기초 데이터셋은 와인 품질 데이터를 예측하기 위한 데이터이다. 이 데이터셋은 Kaggle이나 학교 과제용도로도 굉장히 유명한 데이터이기에 한 번씩 다루어보면 기초 실력을 쌓기에 좋다. 어디서 자료를 찾을 수 있을지 링크를 남겨둘테니, 필요한 사람은 참고해서 사용해보도록 하자.
- 데이터셋 원본 링크 - Red Wine Quality
또한 데이터의 행과 열을 전처리해야 하는 과정이 필요한데, 그 구체적인 과정은 이전 포스팅에서 다루었기 때문에 만약 자신이 아래의 전처리 코드를 보고도 이해가 되지 않는다면, 당장 이글 보다는 전글을 참고하는 것을 강력히 권장한다.
(1) 필요 패키지 및 데이터 import
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
## 기본 패키지 모음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
## 전처리 및 모델링 준비를 위한 패키지
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
## Hyper Parameter 탐색에 사용할 모델
from sklearn.svm import SVC
## 모델 평가를 위한 패키지
from sklearn.metrics import classification_report
from sklearn import metrics
df = pd.read_csv('winequality-red.csv')
wine = df.copy()
|
cs |
(2) 데이터 전처리를 위한 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
## Step1. Interval Scale을 Ordinal Scale로 전환
bins = (2, 6.5, 8)
group_names = ['bad', 'good']
wine['quality'] = pd.cut(wine['quality'], bins = bins, labels = group_names)
## Step2.Label Encoding을 통한 텍스트 Boolean 값의 치환
label_quality = LabelEncoder()
wine['quality'] = label_quality.fit_transform(wine['quality'])
## Step3.종속변수와 독립변수의 분류
x = wine.drop('quality', axis = 1)
y = wine['quality']
## Step4. Train & Test Set의 분류
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
|
cs |
- 코드 논리 요약
- Step1. 와인의 품질을 Good과 Bad로 나누기 위해서 pandas cut을 활용하여 데이터 분류
- Step2. 모델링에 활용할 수 있는 Boolean 값으로 나누기 위해서 Label Encoding을 통한 Good & Bad 치환
- Step3. 모델이 학습을 할 수 있도록 종속변수와 독립변수의 분류
- Step4. 학습 및 평가에 활용할 데이터를 나눌 수 있도록 Train Test set의 분류
만약 위의 과정들이 한 번에 이해되지 않는다면, 아래의 내용을 읽는 것보다는 Machine Learning의 이론 학습을 더 하고 오는 것을 권장한다.
2. Grid Search에 사용할 모델 선택 - SVM
(1) SVM(Supportive Vector Machine)의 기초 소개 - 통계학 기초

SVM 모델은 한마디로 요약하면 데이터들을 분류(Classification)할 수 있는 최적의 선을 찾는 과정이다. 만약 이상적인 선이 그어졌다면, 학습되는 데이터와 분류되는 선 간의 거리를 최대화시킬 수 있을 것이다.
모든 Vector와 선 간의 거리를 최대화시킬 수 있는 거리를 계산하려면 2 / ||W||를 최대화 시키는 것이 통계적으로 SVM 모델의 목표가 되는 것이다.
그렇다면 이 거리의 최대값을 구하려면 분모에 해당하는 ||W|| 값을 최소화시켜주는 알고리즘이 필요하다. 그것을 조금 더 아래와 같이 수식적으로 표현해보겠다.

여기서는 SVM의 모델의 강의가 핵심 목적이 아니기 때문에 아주 간단한 얘기만 하고 넘어가도록 하겠다. 그래서 모델 학습에서 가장 중요한 것이 몇 번 실수로 분류된 데이터가 있는지, 그 값을 최소화 시킬 수 있는 값을 구하는 것이 파라미터를 튜닝하는 과정이다.
이런 식으로 Data Science를 공부하는 사람이라면 Grid Search를 최적으로 찾기 위해서는 사용할 모델의 이론적인 이해가 반드시 선행되어야 한다. 그래야 보다 효율적으로 모델이 낼 수 있는 퍼포먼스를 최대로 이끌어낼 수 있다.
3. GridSearchCV를 통한 Hyper Parameter를 찾는 과정
(1) Hypterparameter 튜닝 이전 결과
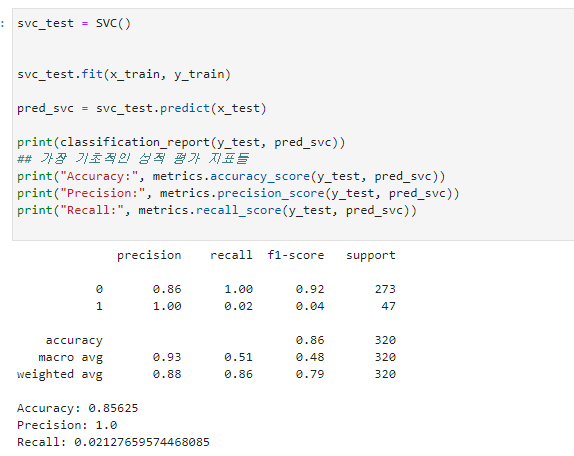
우선 모델 성과 개선 평가를 위해서 아무런 설정 없이 기초 파라미터만으로 결과를 산출했다. Accuracy 기준으로 보면 0.85의 퍼포먼스를 보여주었다. 그러나 이것이 SVM이 가지고 있는 최대치가 아니기에 여기서 머신러닝을 마칠 수는 없다. 이때 바로 사용하는 것이 여러 가지 파라미터를 넣어보면서 학습 결과를 비교 평가하는 것이다.
하지만 무수히 많은 파라미터 경우의 수 조합이 있기 때문에 사람이 하나하나 다 파악하는 것은 무리가 있다. 이럴 때 사용하는 것이 바로 GridSearchCV를 활용한 최적 파라미터 탐색이다.
(2) GridSearchCV의 기초 사용 및 실전 활용
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
## Step1. 모델의 선언
svc_grid = SVC()
## 튜닝에 사용할 파라미터 나열
param_grid = {
'C': [0.1,0.8,0.9,1,1.1,1.2,1.3,1.4]
, 'kernel':['linear', 'rbf']
, 'gamma' :[0.1,0.8,0.9,1,1.1,1.2,1.3,1.4]
}
## KFold Cross Validation을 통한 모델 퍼포먼스 보증
kf = KFold(random_state = 30
, n_splits = 10
, shuffle = True)
## Grid Search 모델의 선언
grid_search = GridSearchCV(estimator = svc_grid
, param_grid = param_grid
, cv = kf
, verbose = 2
)
## Grid Search를 활용한 학습 진행
grid_search.fit(x_train, y_train)
|
cs |
- Grid Search 기초 활용 방법
- Step1. 사용할 모델의 선언
- Step2. Model 안에 설정할 수 있는 파라미터 값을 나열하기
- SVM 안에는 다양한 파라미터가 있지만, 이번 실험에서 사용할 것들은 C, kernel, 그리고 gamma이다.
- 자신이 생각하기에 Performance에 영향을 줄 수 있을 만한 모든 조합을 나열하는 것이 중요하다.
- Step3. KFold 교차 검증을 통한 모델의 학습 성과 높이기
- KFold 교차 검증은 학습 및 평가하는 데이터를 K개로 쪼개서 Iteration을 돌려가며 모델을 평가하는 방법
- 이 방법의 장점은 비교적 개수가 적은 데이터에 대해서 학습 정확도를 높일 수 있다.
- Step4. Grid Search를 통한 학습 진행 - 사용할 변수의 기초적인 설명
- estimator: 여기에는 자신이 선언한 모델을 넣어주면 된다.
- param_grid: 아까 나열한 파라미터의 Dictionary를 삽입해야 한다.
- CV: 교차 검증에 대한 방법론이다. 방금 선언한 KFOLD 변수가 들어가야 한다.
- verbose: 이것은 지금 학습하는 현황을 얼마나 자주 보여줄 것인가 설정하는 것이다. 양수 값을 넣으면 되고, 아주 간단히 말해서 높으면 더 많이 메시지를 볼 수 있다.
- Grid Search에서 활용하면 좋은 메소드 모음
| fit(X[, y, groups]) | 모델의 피팅 과정 |
| get_params([deep]) | 모델이 학습한 파라미터의 반환 |
| predict(X) | 새로운 데이터에 대해서 예측 진행 |
| score(X[, y]) | 학습한 성과의 점수를 반환 |
| set_params(**params) | 모델에 사용될 파라미터 설정 |
| transform(X) | 가장 최적으로 찾은 파라미터를 기반으로 데이터를 변환 |
| best_params_ | 모델이 학습한 결과 중 가장 최적의 파라미터를 산출 |
여기서 다른 건 몰라도 반드시 알아야 할 것은, fit, predict, transform 그리고 best_params_이다. 왜냐하면 학습한 파라미터들에 대해서 평가를 하고, 그 값이 무엇인지 조회할 줄 알아야 다음 단계를 진행할 수 있기 때문이다.
(3) Hypterparameter 튜닝 이후 결과 비교
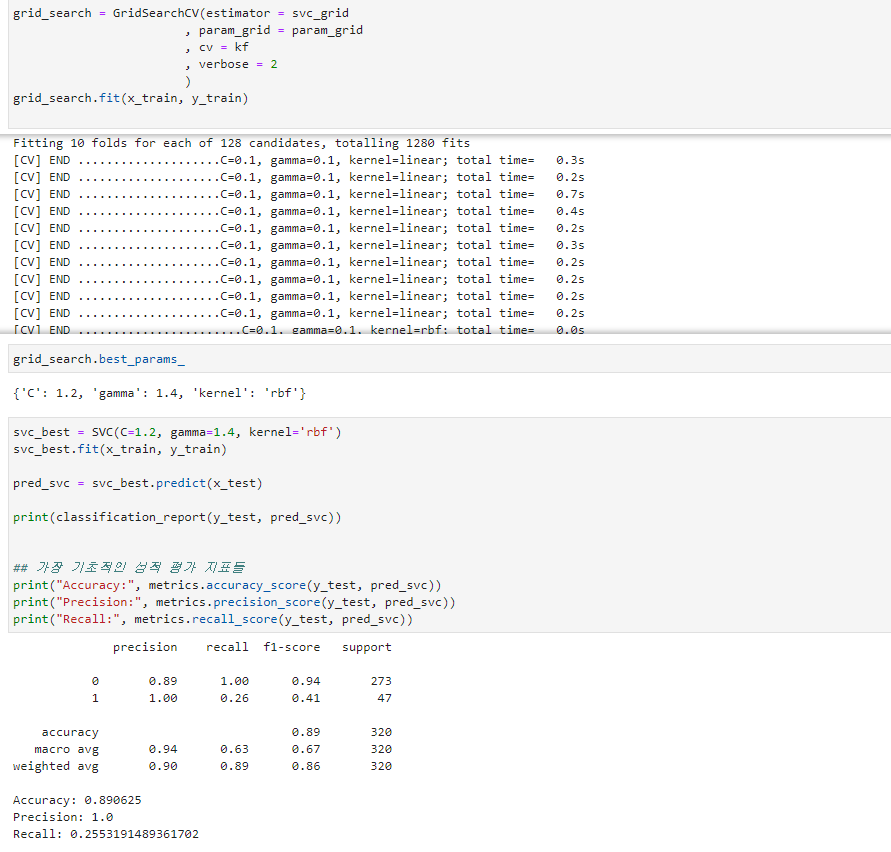
- 테스트 결과 보고
- Output 결과를 봤을 때 내가 설정한 파라미터들은 총 1,280개의 경우의 수를 테스트하였다.
- 그 결과 best_params_를 통해 찾은 Optimal Parameter는 위의 사진과 같았다.
- 최적 파라미터 재학습 결과 모델의 전반적인 Performance가 개선된 것을 관측하였다.
- Accuracy: 0.85 → 0.89
- Precision: 1로 결과 동일
- Recall: 0.02 → 0.25
- 이 파라미터는 특히나 Recall Score을 개선시키는데 성공하였다. 따라서 이번 ML 실험은 성공이라고 판단할 수 있다.
이때까지 어떻게 하면 Machine Learning 결과를 극대화할 수 있는지 이론과 코드를 기반으로 설명했다. 그대들의 과제에 성과가 있기를 바라면서 이 글을 마친다.
'빅데이터 분석 > 기초 모델링 연습' 카테고리의 다른 글
| 기초 모델링 연습. 와인 품질 예측을 위한 모델링(Wine Quality Prediction) (0) | 2020.12.31 |
|---|
