1. 데이터 기본 설명 - Wine Quality
2. 모델링을 위한 기본 프로세스 설명
3. 실제 모델링을 위한 코드
4. 코드 한 줄 정리
1. 데이터 기본 설명 - Wine Quality
이번 시간에는 모델링의 기초 중에 기초를 복습하는 차원에서 쉽고 유명한 데이터를 가져왔습니다.
이 데이터의 목적은 와인의 품질을 예측하는데 목적을 두고 있습니다.
데이터의 출처는 삽입되어 있는 주소로 따라가지면 편하게 다운 받을 수 있습니다.
각종 변수들은 산도, 알콜 농도, 잔여 당분 등 여러 가지 변수가 있습니다. 원래는 데이터 특성에 대한 심층적인 탐구가 이루어진 이후에 모델링으로 들어가는 것이 맞지만, 이번 포스팅은 "아 모델링은 이러한 과정을 거쳐서 이루어지는구나~"에 초점을 맞추기 때문에 최대한 단순하게 넘어가도록 하겠습니다.
2. 모델링을 위한 기본 프로세스 설명
기초적인 모델링을 할 때는 아래의 순서와 같이 보통 진행됩니다.
(물론 심화과정으로 가면 달라집니다!! 초보를 위한 기초 이해라는 것을 감안해주세요~)
(1) 연구 주제의 설정
이번 연구의 목적은 "와인의 품질이 좋은지 나쁜지 예측할 수 있는 모델을 수립"하는 것입니다.
이러한 초기 연구 방향성을 잘 설정하셔야 데이터 전처리부터 최적 모델 선택까지 수월하게 이루어질 수 있으니, 간단하게 보여도 절대로 빼먹으면 안 되는 부분 중에 하나입니다.
이러한 연구 주제를 조금 더 데이터 사이언스적으로 풀어보면
" 종속변수가 2가지 경우의 수인 Binary Classification 연구이므로, ML Model 중 Classification Model에 대해 학습을 시킨다"로 정리할 수 있습니다.
상세한 설명은 아래와 같습니다.
1) Binary Classification(이진 분류)
이진 분류라 함은 종속변수의 경우의 수가 2가지인 경우로, 가장 쉬운 예를 들면 동전의 앞면과 뒷면이 있습니다.
여기서도 연구 주제가 "좋은지 나쁜지" 두 가지 경우의 수밖에 존재하지 않습니다. 따라서 이 연구는 분류(Classification)의 문제로 접근을 해야 합니다.
ML(Machine Learning, 기계학습)에서 분류(Classification)에서 사용되는 가장 기초적인 모델들이 있습니다.
베이지안, 로지스틱 회귀(Logistic Regression), SVM, KNN, Decision Tree이 있습니다.
따라서 이 포스팅에서는 간단하게 저 모델들을 어떻게 적용할 수 있는지 소개하도록 하겠습니다.
물론 현재 가장 핫한 모델들 중에 xgboost, lgbm 등이 있지만, 해당 포스팅은 기초 모델의 적용에 초점을 맞춰 있기에 생략하도록 하겠습니다.
(2) 데이터의 탐구 및 전처리 계획
1) 와인의 품질
해당 데이터에서는 와인의 품질이 0 ~ 10까지 품질평가가 이루어졌고, 실제로 들어있는 데이터는 최소 3부터 최대 8점까지 들어있습니다.
이번 연구 주제는 "좋은지 나쁜지"를 확인하는 것이기 때문에 이러한 scale(척도)를 이진분류로 바꿔줄 필요가 있겠네요. 이러한 사항을 꼼꼼히 기록해서 데이터 전처리에 반영하는 것이랍니다.
2) 변수간 상이한 척도
해당 데이터는 다양한 변수들이 들어 있습니다.
예를 들어 알콜 농도와 산도를 측정하는 변수가 있는데, 이 두 변수를 그냥 그대로 비교하고 써도 될까요??
정답부터 말씀드리면 그렇게 하면 심각한 오류를 범할 수도 있습니다. 왜냐하면 우리가 알고 싶은 것은 변수 간의 영향력을 보다 객관적으로 측정하여 종속변수에 끼치는 영향을 알아야 되기 때문입니다.
좀 더 쉬운 예를 들어서, 소금과 식초가 음식 맛에 미치는 영향을 알아보는데, 소금의 단위는 mg 혹은 g단위이고, 식초는 ml 혹은 L 단위입니다. 그렇다면 1g의 소금이 식초 10ml보다 영향이 많이 끼치는지 알기 위해서는 두 단위를 "표준화"시켜야할 필요가 있다는 뜻이죠.
그래서 "변수들의 단위 간 표준화 작업을 실시할 예정"입니다.
(3) 모델 학습을 위한 준비 및 모델 학습
1) 모델학습을 위한 데이터의 분류
모든 모델링을 실시하기 이전에 데이터를 분류하는 작업을 해야 합니다.
쉽게 말해서, 학습 시킬 데이터와 진짜로 제대로 예측을 하는지 시험을 보는 데이터로 나누는 것입니다.
| 항목 | 훈련을 위한 데이터 | 정답 채점을 위한 데이터 |
| x | x_train | x_test |
| y | y_train | y_test |
x_train과 y_train을 기반으로 모델을 학습시킵니다. 이를 기반으로 모델은 이 데이터를 어떻게 하면 잘 예측할 수 있는지 스스로 배우는 것이죠.
이제는 진짜 잘 배웠는지 테스트를 하는 단계로 넘어가야 합니다. 그래서 x_test를 모델에 적용시켜 모델이 산출한 정답(Prediction)을 내놓습니다. 이 Prediction 값을 실제 데이터 y_test와 비교 평가를 함으로써 최종적인 모델의 성적이 나옵니다.
2) 대상 모델 정리
이번 포스팅에서 다룰 모델들은 Random Forest, SVM, Logistic Regression, Decision Tree, KNN, 그리고 Naive Bayseian모델입니다.
해당 모델들은 Classification에서 가장 흔히 사용되는 모델들입니다. 여기서는 파라미터 튜닝이나 최적화 과정을 거치지 않고, 디폴트로 설정된 파라미터만 사용할 것입니다.
대신 많은 모델들을 적용하는 것을 소개함으로써 어떻게 모델링이 진행되는지 몸에 익히는 시간을 갖도록 하겠습니다.
(4) 모델의 성능 평가 및 결과 시각화
Classification 모델 성능평가에 있어서 다양한 척도가 있습니다. 예를 들어, precision, recall, f1 score, accuracy 등의 지표가 있습니다. 여기서는 가장 간단하고 이해하기 쉬운 Accuracy를 사용하도록 하겠습니다.
Accuracy란 틀린 것을 틀리다고 답하고, 맞는 것을 맞다고 대답한 비율을 의미합니다. 예를 들어, 10개 중에 8개를 제대로 분류했으면 Accuracy는 80%가 되는 것이죠.
그리고 해당 모델들이 학습한 결과 독립 변수 중에서 그래서 누가 가장 중요한 변수로 작용했는지 알고 싶을 때가 있을 것입니다. 그래서 이를 위한 시각화 작업도 진행하도록 하겠습니다.
3. 실제 모델링을 위한 코드
(1) 기본 패키지 모음
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
## 기본 패키지 모음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
## 전처리 및 모델링 준비를 위한 패키지
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
## 실제 모델링을 위한 패키지
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
## 모델 평가를 위한 패키지
from sklearn.metrics import classification_report
from sklearn import metrics
df = pd.read_csv('winequality_red.csv', sep = ';')
|
cs |
제가 이번 모델링을 위해서 사용한 패키지는 위와 같습니다.
(2) 데이터 전처리를 위한 코드
1) 종속변수의 변환
|
1
2
3
4
5
6
7
8
9
|
## 6.5점을 기준으로 좋은 와인과 나쁜 와인을 구분하겠다고 선언
bins = (2, 6.5, 8)
group_names = ['bad', 'good']
wine['quality'] = pd.cut(wine['quality'], bins = bins, labels = group_names)
## 굿 배드는 인식할 수 없음. 따라서 이를 인식할 수 있도록 Label Encoding을 실시
label_quality = LabelEncoder()
wine['quality'] = label_quality.fit_transform(wine['quality'])
|
cs |
위의 코드에서 배워볼만한 기능은 두 가지가 있습니다.
첫 번째는 pd.cut의 기능입니다. 일정 기준으로 재분류할 때 정말 유용하게 쓰이는 코드입니다. 만약 이거를 사용하지 않는다면, for 문으로 복잡하게 작업을 실시해주어야 하지만, pd.cut 함수를 쓰게 되면 복잡한 코드가 한 줄에 끝날 수 있는 것이죠.
두 번째는 LabelEncoder()라는 패키지 함수입니다. 위에서 와인 품질은 "좋음"과 "나쁨"으로 나누었습니다. 그러나 컴퓨터 입장에서는 이거는 외계어일뿐 알아들을 수 있는 형태의 언어가 아닙니다. 따라서 이러한 것을 컴퓨터의 언어로 바꿔줄 필요가 있죠
조금 더 정확히 말해서 이진분류의 종속변수이기 때문에 Dummy Variable(더미 변수)로 나누어주어야 하고, 이는 분류를 0과 1로 할 수 있는 통계학적 개념입니다.
wine['quality'] = label_quality.fit_transform(wine['quality'])
위의 코드로 더미 변수로 변환해주었고, 데이터셋을 한 번 확인해보겠습니다.
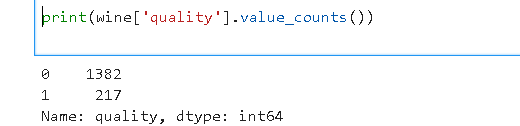
확인해본 결과 217개의 품질 좋은 와인이 있고, 1382개의 품질이 떨어지는 와인이 있는 것을 확인할 수 있네요.
(3) 데이터 셋의 분리 및 척도 표준화
1) 데이터셋의 분리
|
1
2
3
4
5
6
7
|
##종속변수와 독립변수를 나누어주는 작업
x = wine.drop('quality', axis = 1)
y = wine['quality']
## 변수별로 Train과 Test 쓸 데이터 셋을 분류x
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
|
cs |
여기서 기억하실 부분은 바로 가장 마지막 부분입니다. 이 코드는 모델링을 하시는 분들이라면 언제나 암기하고 있고 있으실 것이라 생각합니다.
저 한 줄의 코드가 거의 모든 데이터 셋 학습에 쓰이니, 처음 보신 분들은 우선적으로 암기하는 것도 추천드립니다.
위에서 제가 하나의 표로 설명드린 부분이 있죠. 그 표를 코드로 표현하면 바로 위의 코드가 되는 것입니다.
2) 척도의 표준화
|
1
2
3
4
|
## 측정 지표의 표준화.
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.fit_transform(x_test)
|
cs |
척도의 표준화를 시킬 때는 StandardScaler()라는 패키지를 사용해서 하시면 아주 쉽게 적용하실 수 있습니다.
여기까지 하면 바로 모든 모델 학습을 위한 데이터를 준비를 마친 것입니다.
(4) 모델의 학습 및 평가
모든 모델의 학습 및 평가는 총 3 단계로 비교적 단순하게 진행됩니다.
1단계. 모델의 선언
2단계. 학습데이터의 모델 학습
3단계. 결과 평가
자 이제 위에서 소개한 모델들을 어떻게 학습시킬 수 있는지 차례 차례 보도록 하겠습니다.
1) Random Forest
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
## 모델의 선언
rfc = RandomForestClassifier(n_estimators=200)
## 학습데이터의 모델 적용
rfc.fit(x_train, y_train)
## 모델의 예측값 산출
pred_rfc = rfc.predict(x_test)
## 다양한 모델 평가
print(classification_report(y_test, pred_rfc))
## 가장 기초적인 성적 평가 지표들
print("Accuracy:", metrics.accuracy_score(y_test, pred_rfc))
print("Precision:", metrics.precision_score(y_test, pred_rfc))
print("Recall:", metrics.recall_score(y_test, pred_rfc))
|
cs |
위의 코드를 실행하면 아래의 결과처럼 산출됩니다.

Random Forest 같은 경우 Default Parameter들로 학습을 시켰을 때 Accuracy가 0.88로 비교적 준수한 예측 성능을 보여주네요.
과연 Random Forest에서는 어떠한 변수를 중요하게 판단했는지 알아보고 싶을 수도 있겠죠. 그럴 때는 하나의 함수를 선언하여 시각화해서 표현하면 정말 유용하게 쓸 수 있습니다.
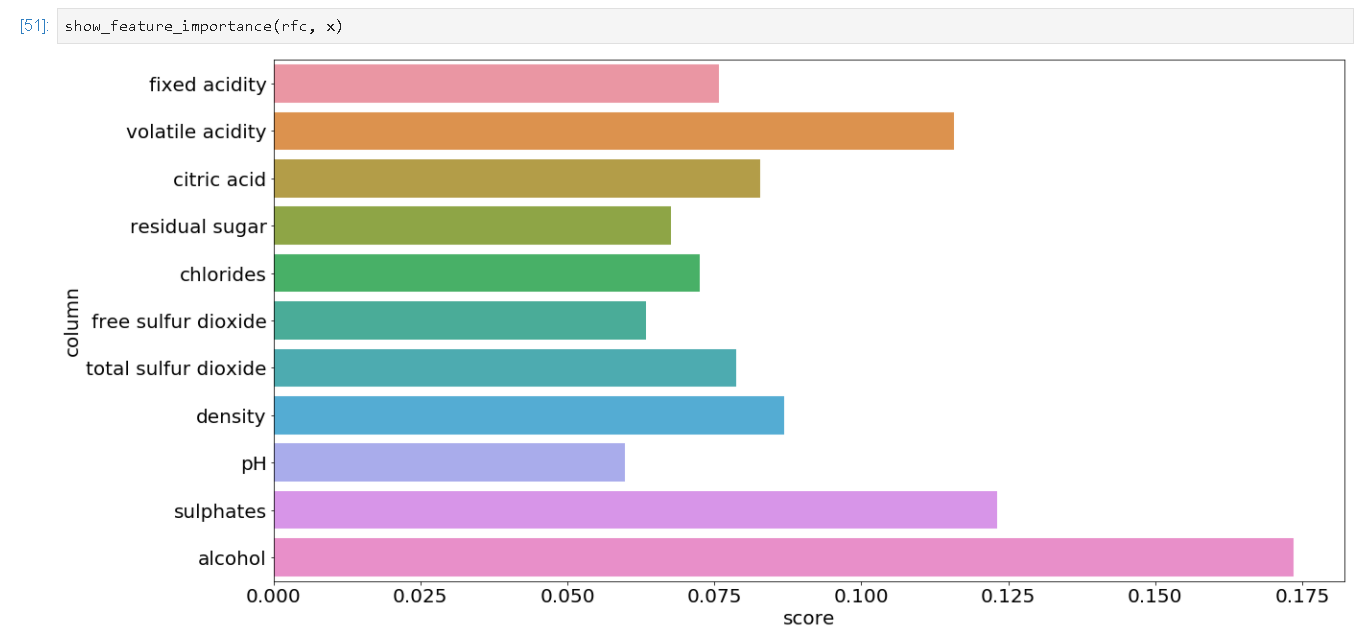
Random Forest에서는 알콜 농도와 Volatile 산도를 가장 중요한 변수로 판단을 하여 학습을 했네요. 이런 식으로 모델 내 다양한 method를 사용하면 원하는 데이터 수치를 보실 수 있습니다.
모든 모델들에 대해서 이제 자세하게 설명하기보다는 바로 보고 적용하실 수 있도록 코드 위주로 설명해보도록 하겠습니다.
2) Support Vector Model
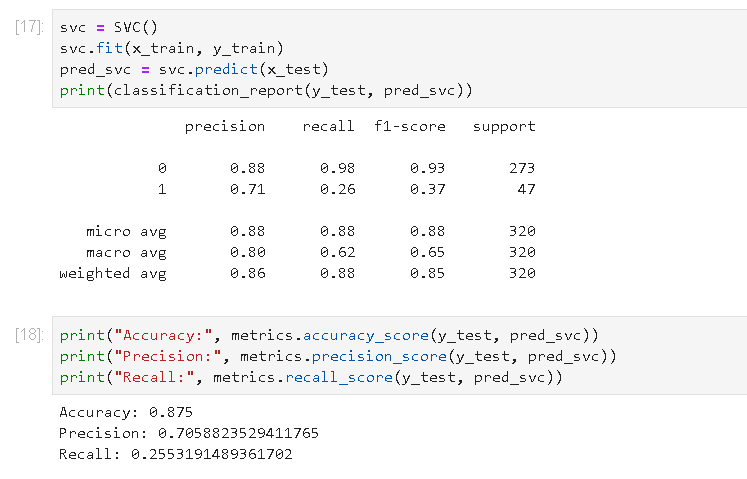
3) Logistic Regression

4) Decision Tree 모델
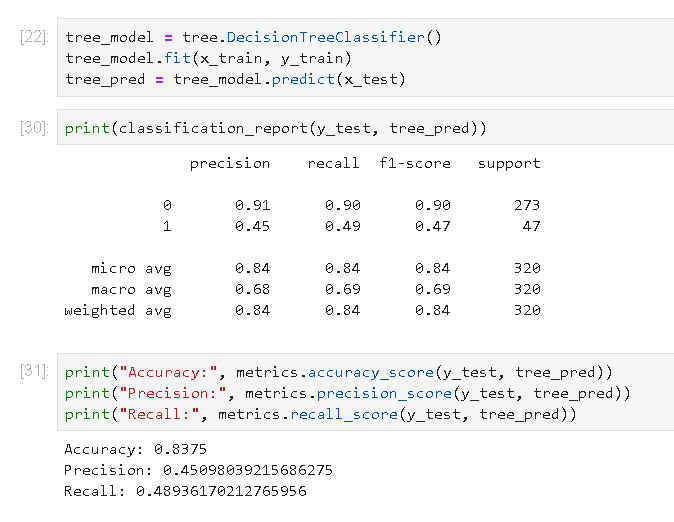
5) KNN 모델의 학습
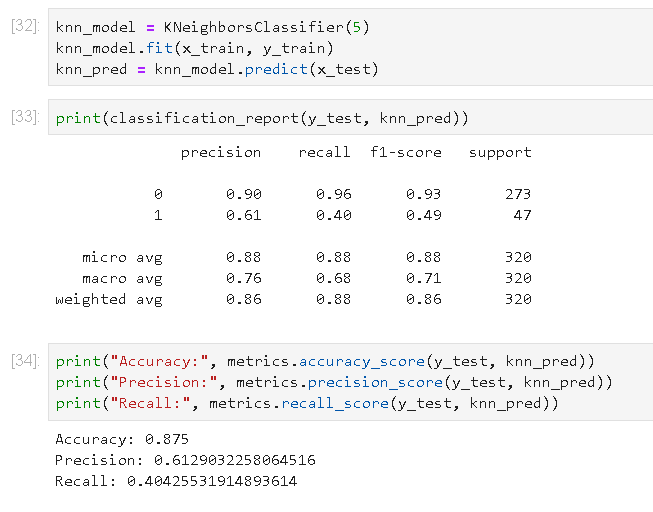
6) Naive Bayesian 모델
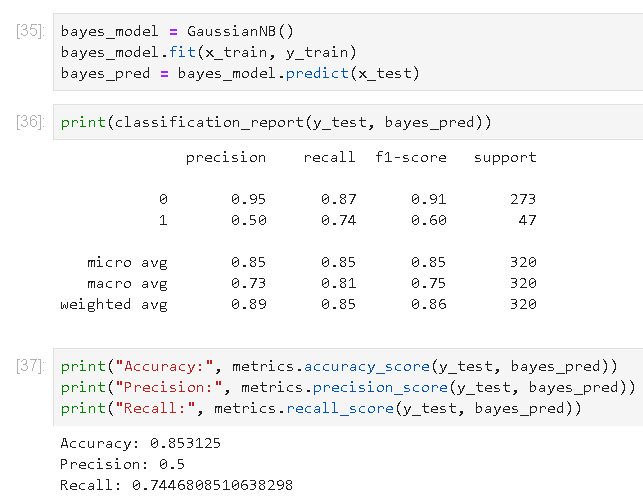
네 이런식으로 원하는 모델에게 학습을 시킬 수 있습니다.
여기까지 모델링이 과연 무엇이고 어떻게 진행하는 것인가에 대해서 정말 맛보기만 해봤습니다.
다음에는 정말 어떻게 최적 모델을 찾을 수 있고, 최적 모델에서는 파라미터를 튜닝을 해서 결과 값을 어떻게 하면 최대로 정확하게 예측할 수 있는지에 대해서 다루어보도록 하겠습니다.
항상 정독하지 마시고, 원하는 것만 찾아가시길 바랄게요!!
