최근에 Selenium4로 업데이트 되면서 기존에 짜놓은 코드가 돌아가지 않는 현상을 겪고 있고, Instagram도 Frontend 로직이 바뀌면서 많은 독자가 어려움을 겪었다. 그래서 이번에 Selenium4와 최신 코드를 기준으로 자동으로 정보를 긁어올 수 있는 크롤러를 새로 개발하여 공개하고자 한다.
목차
1. 셀레니움 설치 및 기본 함수 소개
2. 셀레니움으로 인스타그램에 로그인하기
3. 인스타그램 크롤링 코드 Logic 설명
4. Pandas를 활용한 DataFrame 형성
5. 전체 코드 소개
1. 셀레니움 설치 및 기본 함수 소개
- 자신의 컴퓨터에 셀레니움 설치하는 방법
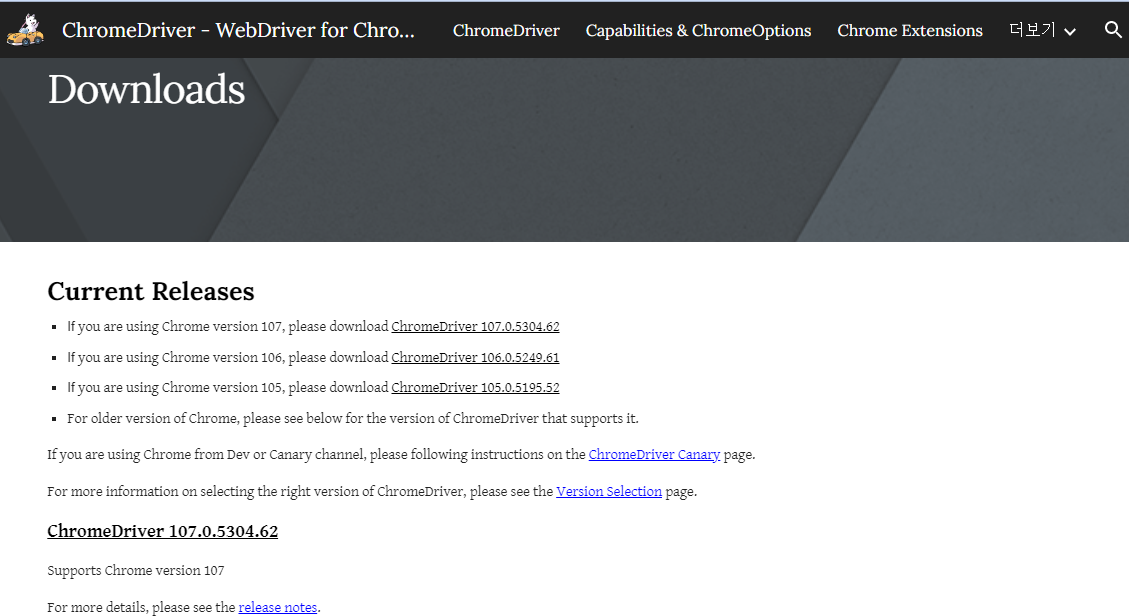
셀레니움4를 설치할 때는 두 가지 사항만 진행하면 아주 간단하게 할 수 있다. 첫 번째는 로컬 환경 내에 pip install selenium 명령어로 설치하는 것이고, 두 번째는 자신의 크롬 버전에 맞는 드라이버를 설치해주면 사실상 모든 준비는 끝나게 된다. 드라이버는 이 주소에서 다운받을 수 있으니 참고하길 바란다. 참고로 이 포스팅은 Anaconda Jupyter Lab 환경에 최적화가 되어있다.
 |
 |
- 이번 크롤링 코드에 사용할 패키지 모음
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import requests
from bs4 import BeautifulSoup
import pymysql
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import getpass
import urllib.request
import random
from time import sleep
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
|
cs |
이번 크롤링에 사용한 모든 패키지이다. 미리 설치하면 포스팅 내용을 따라가는데 도움이 될 것이다. 사실 없어도 되는 패키지가 몇 개 섞여 있는데 알아서 잘 사용하길 바란다.
- 셀레니움에서 사용할 수 있는 기본 Locator 소개
이번 업데이트가 되면서 가장 어려움을 겪고 있는 부분이 바로 Locator 명령어가 다 바뀌었기 때문에 기존 코드들이 다 무효화된 것이다. 본격적인 크롤링 코드로 들어가기 전에 어떤 Element Finder들이 있고, 구체적인 문법은 어떻게 되는지 반드시 학습하고 들어가야 코드를 이해할 수 있을 것이다.
| Locator | 설명 | 코드 |
| CLASS_NAME | 클래스로 정의된 요소를 찾아서 값을 반환한다. | driver.find_element(By.CLASS_NAME, "원하는 클래스") |
| CSS_SELECTOR | CSS와 일치하는 HTML을 검색하여 값을 반환한다. | driver.find_element(By.CSS_SELECTOR, "원하는 CSS") |
| ID | 일치하는 ID값을 찾아준다. | driver.find_element(By.ID, "원하는 ID값") |
| NAME | NAME이 동일한 요소를 찾아준다. | driver.find_element(By.NAME, "원하는 Name 값") |
| LINK_TEXT | 입력한 텍스트 값과 일치하는 요소를 검색하여 반환한다. | driver.find_element(By.LINK_TEXT, "원하는 값") |
| TAG_NAME | Tag를 기준으로 HTML 내 요소를 검색한다. | driver.find_element(By.TAG_NAME, "원하는 Tag 값") |
| XPATH | XPath 식과 일치하는 요소를 검색하여 반환한다. | driver.find_element(By.XPATH, "원하는 Path 값") |
참고로 찾고자하는 요소가 복수로 이루어져 있다면, find_element에서 find_elements 로 복수형으로 쓰면 HTML에 있는 모든 요소를 반환하니 참고하길 바란다. 또한 여기서는 대소문자도 구분하니 반드시 철저하게 문법을 지켜야만 코드가 작동한다는 것을 기억하기 바란다. 이번 크롤링 코드에서는 CLASS_NAME을 활용하여 코드를 구성하였으니 참고하길 바란다.
2. 셀레니움으로 인스타그램에 로그인하기
- 크롬 드라이버로 자동제어창 열고 인스타 그램에 들어가기
- (1) 주석 설명
: webdriver의 크롬을 앞으로 driver라는 변수로 정의한 것이다. 따라서 앞으로 driver로 시작하는 코드는 모두 자동 제어창에게 특정 행동을 하도록 명령하는 것이니, 반드시 이 변수를 기억해야 한다. - (2) 주석설명
: 위에서 선언한 driver 변수에 인스타그램 로그인 페이지로 이동하라고 명령을 내린 것이다. 밑에 있는 maximize_window는 인터넷 창을 최대로 키우라는 간단한 명령어다. - (3) 주석 설명
: getpass 패키지는 입력하는 값을 비밀리에 입력할 수 있는 아주 유용한 함수이다. 이것은 필수적인 사항은 아니지만 알고 있으면 좋기 때문에 이번 크롤링 코드에 반영하였다. - (4) 주석 설명
: (3)에 입력한 정보를 이제 driver 창으로 옮겨서 각 ID와 PW에 해당하는 값을 넣으라고 명령한 것이다. 그 이후 "로그인 버튼"에 해당하는 element를 찾아서 클릭 명령을 하게 되면 로그인이 완료되는 것이다.
- (1) 주석 설명
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
## (1) 드라이버 정의
driver = webdriver.Chrome('드라이버 저장 Path\\chromedriver.exe')
## (2) 인스타그램 로그인 페이지로 이동
driver.get("https://www.instagram.com/accounts/login/")
driver.maximize_window()
## (3) 로그인에 필요한 정보 입력
username = getpass.getpass('Input ID: ')
password = getpass.getpass('Input PWD: ')
## (4) ID와 PW에 맞게 요소를 전달
element_id = driver.find_element(By.NAME, "username")
element_id.send_keys(username)
element_password = driver.find_element(By.NAME, 'password')
element_password.send_keys(password)
driver.find_element(By.CLASS_NAME, '_acan._acap._acas').click()
|
cs |
만약 위의 과정에서 문제가 생긴다면 그냥 크롬만 킨 다음에 로그인까지 수동으로 해줘도 무방하니 귀찮은 사람은 그렇게 하길 바란다.
3. 인스타그램 크롤링 코드 Logic 설명
- Part1. 원하는 검색어 주소로 이동 및 데이터 저장소 준비
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
## 데이터를 저장할 Dictionary
insta_dict = {'id':[],
'date': [],
'like': [],
'text': [],
'url': [],
'hashtag':[]
}
## 원하는 검색어 입력한 코드 데려오기
driver.get('https://www.instagram.com/explore/tags/%EC%83%A4%EB%A1%9C%EC%88%98%EA%B8%B8%EB%A7%9B%EC%A7%91/')
sleep(3)
## 첫 번째 게시물 클릭하기
first_post = driver.find_element(By.CLASS_NAME, '_aagu')
first_post.click()
sleep(random.randint(2,4))
|
cs |
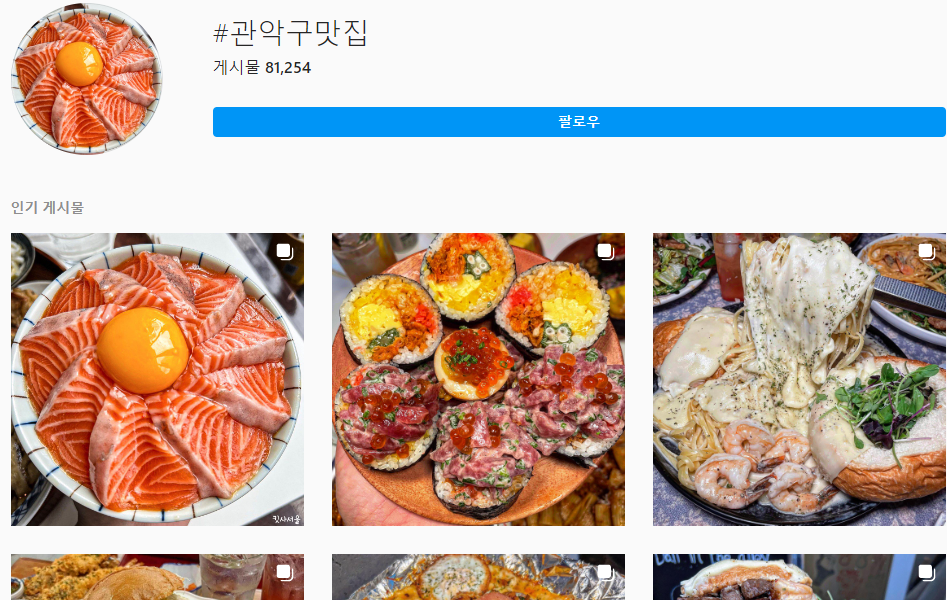
이번 포스팅에서는 "관악구 맛집"이라는 태그가 있는 게시물들에 접근하여 원하는 데이터를 가져오는 작업을 할 것이다. 크롤링에서 수집할 데이터는 아이디, 게시물 작성일, 좋아요 수, 본문, 게시물 주소, 그리고 해시태그들이다.
중간에 sleep이라는 코드가 들어간 이유는 인터넷이 모든 요소를 로드할 때까지 시간이 필요하기도 하고, 너무 빠른 명령어는 사이트에서 접근을 제한할 수 있는 위험도 있기 때문에 방어코드로 항상 들어가 줘야 한다.
이후 첫 번째 게시물까지 클릭하게 된다면, 사실상 거의 모든 준비는 끝나게 되는 것이다. 여기까지 어려움을 겪었다면, 사실 그냥 손으로 들어와도 되니 너무 고생할 필요는 없을 것 같다.
- Part2. 크롤링 기본 Logic 소개
- (1) Loop 상태 확인을 위한 변수
: 여기서는 seq와 check_point를 통해서 원하는 순번까지 갔거나 혹은 Loop 상태가 이상할 때 언제든지 Loop를 빠져나올 수 있도록 기본 변수를 설정하였다. - (2) While문과 Try ~ Except를 활용한 통한 Loop 실행
: While문은 check_point가 True일 때만 실행되게 된다. 또한 Loop가 5회 실행될 때마다 상태를 확인할 수 있도록 출력하는 조건문을 삽입하였다. - (3) Try문을 통한 크롤링 코드 실행
: 여기서는 우선적으로 크롤링을 수행하게 된다. 만약 크롤링에서 문제가 발생하면 except로 빠져나가서 Loop를 계속 실행할지 혹은 빠져나올지 결정하게 된다. - (4) except를 통한 Loop 탈출 방어 코드 구현
: 여기까지 왔다면, Loop가 다 돌았든 에러가 발생했든 그만 두어야 하는 상황이다. 이때 이게 정상적으로 끝난 상황인지 혹은 예측하지 못 한 문제가 발생했는지 파악하기 중요하기 때문에 메시지를 분기처리하였다.
- (1) Loop 상태 확인을 위한 변수
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
## (1) Loop 환경 Check를 위한 변수 선언
seq = 0
check_point = True
## (2) Loop의 시작
while check_point:
if seq % 5 == 0:
print('데이터 수집 순서: {}'.format(seq))
## (3) Level 1 - 크롤링을 수행하기 전에 Loop의 상태를 확인하여 언제든지 빠져나올 수 있는 환경 구축
try:
/*
크롤링 코드 삽입 예정
*/
## (4) Level 1 Try - 다음 게시물이 없다면, check point를 False로 바꿔서 Loop 탈출
except:
check_point = False
if seq == 20:
print('Loop Over')
else:
print('Ooops....something wrong in {}th sequence'.format(seq))
|
cs |
- Part3. 인스타그램에서 원하는 정보를 가져오기
: 이 부분은 위에서 언급한 "크롤링 코드 삽입 예정" 파트에 들어가는 부분이다. 가장 핵심적인 코드이기 때문에 단계별로 주석 설명을 하고자 한다. 그리고 모든 구성 요소를 수집할 때, 에러가 발생할 수 있으니 try ~ except ~ 문을 통해서 모든 요소가 빠짐 없이 들어갈 수 있도록 코드를 작성하였다. 만약에 그 정보가 없다면, column별로 null을 삽입할 것인지 아니면 별도의 string을 삽입할지 구성하였다.
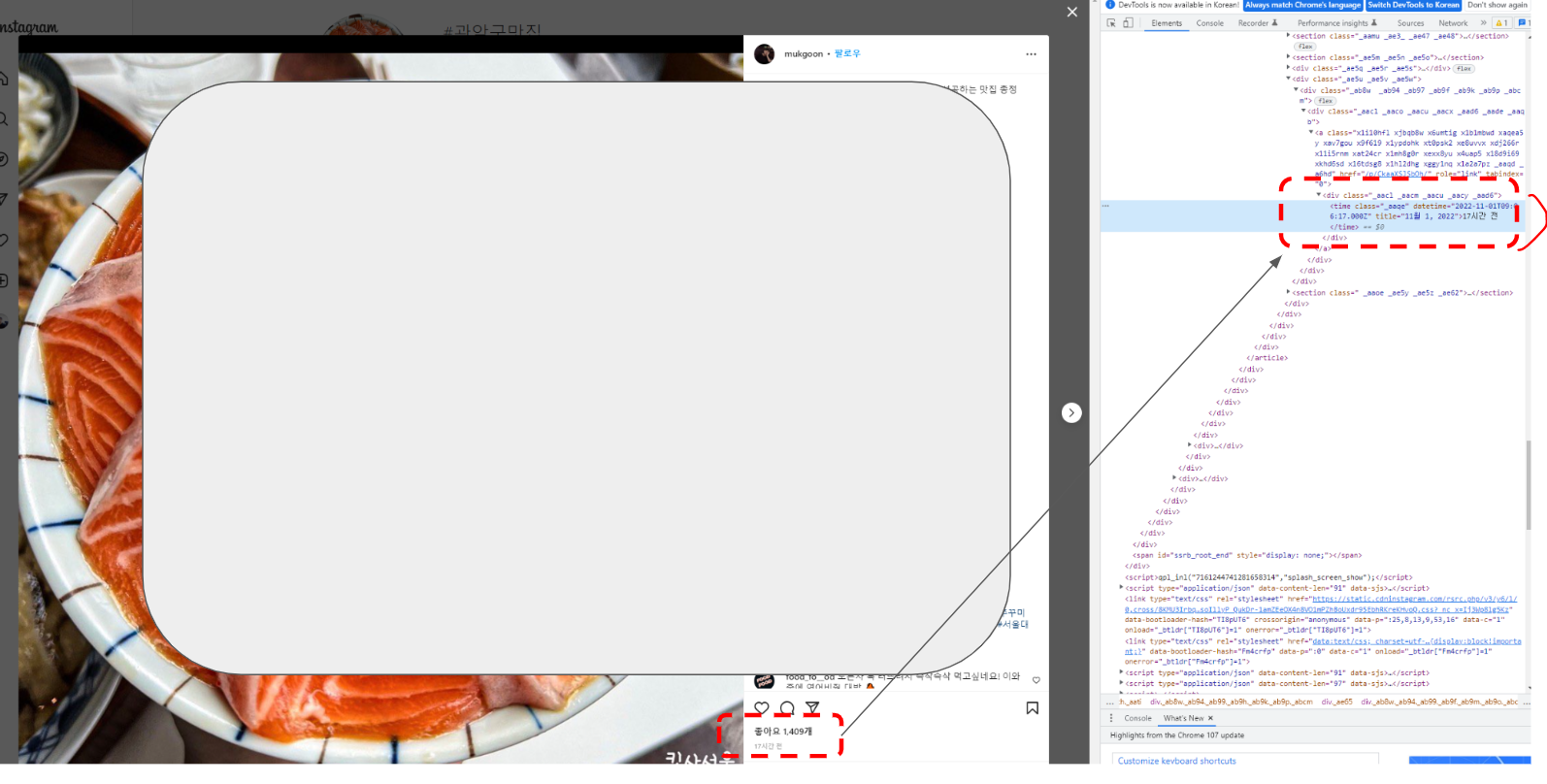
더 쉬운 이해를 하고 싶은 사람은 아래의 두 사진을 참고해보면 될 것이다. 첫 번째 사진은 우리가 현재 크롤링할 화면이다. 두 번째 사진은 개발자 도구에서 각 Class 값을 확인하고 안에 어떤 소스들이 들어가 있는지 직접 볼 수 있는 화면을 보여준 것이다.
- (1) ID 정보 수집
: ID 정보는 _aap6._aap7._aap8라는 클래스에 들어있었기 때문에 이를 활용하였고, text 메소드를 통해서 string 값을 받는 명령문이다. - (2) 본문 텍스트 정보 수집
: Text 정보는 _aacl._aaco._aacu._aacx._aad7._aade 라는 클랙스가 들어있었고, 수집하는 방식은 동일하다. - (3) 게시물 작성 시간
: Date 정보는 _a9ze._a9zf 에 들어있었다. 여기서의 핵심은 date가 안에 속성값으로 들어가 있었기 때문에 get_attribute라는 별도의 함수를 적용하였다. 이는 F11 값을 누르고 제어창을 보면 이해가 빠를 것이다. - (4) Hashtag 정보 수집
: 이 정보는 class 이름이 지나치게 길었기 때문에 별도의 string 값으로 받았다. 참고로 HTML에서는 ' '로 되어있는 부분은 '.'으로 바꿔주어야 크롤링이 된 반드시 기억하길 바란다. - (5) 좋아요 정보 수집
: 이 정보도 귀찮기 때문에 string 값을 받고 안에 있는 세부 string 값을 dot(.)으로 변환해주었다. - (6) 현재 URL 수집
: 현재 URL 정보를 받기 위해서는 driver.current_url 메소드를 활용하면 아주 쉽게 가져 올 수 있다. - (7) 정보 수집 끝나서, Health check 하기
: 여기까지 진행되었다면, 이제 1회 Loop에서 모든 필요한 정보를 받은 것이다. 따라서 1회가 끝났음을 알려주기 위해서 seq에 1을 더하였다. 이제는 다음 게시물로 넘어가기 위해서 다음 버튼을 자동으로 클릭해주어야 하고, 이를 수행하기 위해서 필요한 class는 '_aaqg._aaqh' 였다.
다음 버튼을 누른 후 JavaScript가 정보를 불러올 시간이 필요하기 때문에 반드시 몇 초 쉬었다가 다음 Loop 작업을 수행해야 한다. 또한 너무 일정한 패턴을 보이면 Abusing으로 보일 수 있기 때문에 쉬는 시간을 랜덤하게 설정하였다.
- (1) ID 정보 수집
※ 참고 - 사진을 통한 크롤링 환경의 이해
 |
 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
## (1) ID 정보 수집
try:
## ID Class Name
id_info = driver.find_element(By.CLASS_NAME, '_aap6._aap7._aap8').text
insta_dict['id'].append(id_info)
except:
insta_dict['id'].append('error')
## (2) 본문 텍스트 정보 수집
try:
## Text Class Name
text_info = driver.find_element(By.CLASS_NAME, '_aacl._aaco._aacu._aacx._aad7._aade').text
insta_dict['text'].append(text_info)
except:
text_info = 'no_text'
insta_dict['text'].append(text_info)
## (3) 게시물 작성 시간 정보 수집
try:
## 시간 정보 수집
time_raw = driver.find_elements(By.CLASS_NAME, '_a9ze._a9zf')
time = pd.to_datetime(time_raw[0].get_attribute('datetime'))
insta_dict['date'].append(time)
except:
insta_dict['date'].append('error')
## (4) Hash Tag 정보 수집
try:
## Hashtag
hash_link = 'x1i10hfl xjbqb8w x6umtig x1b1mbwd xaqea5y xav7gou x9f619 x1ypdohk xt0psk2 xe8uvvx xdj266r x11i5rnm xat24cr x1mh8g0r xexx8yu x4uap5 x18d9i69 xkhd6sd x16tdsg8 x1hl2dhg xggy1nq x1a2a7pz _aa9_ _a6hd'
hash_link = '.'.join(hash_link.split(' '))
f_hash = driver.find_elements(By.CLASS_NAME, hash_link)
tag_list = [ f_hash[i].text for i in range(len(f_hash)) ]
insta_dict['hashtag'].append(tag_list)
except:
insta_dict['hashtag'].append('no_tag')
## (5) 좋아요 정보 수집
try:
like_raw = '_aacl _aaco _aacw _aacx _aada _aade'
like_raw = '.'.join(like_raw.split(' '))
like_text = driver.find_element(By.CLASS_NAME, like_raw).text
like_number = int(re.findall('[ 0-9]+' , like_text)[0])
insta_dict['like'].append(like_number)
except:
insta_dict['like'].append('error')
## (6) 현재 URL 수집
try:
current_url = driver.current_url
insta_dict['url'].append(current_url)
except:
insta_dict['url'].append('error')
seq += 1
## (7) 정보 수집 끝나서, Health check 하기
driver.find_element(By.CLASS_NAME, '_aaqg._aaqh').click()
## 다음 게시물 클릭하고 기다리기
pause_time = round(random.uniform(2.4, 3.9), 3)
sleep(pause_time)
|
cs |
Part3의 코드를 Part2에 소개한 부분 중에서 "크롤링 삽입 코드"에 넣으면 완벽하게 크롤링 Loop가 실행될 것이다.
4. Pandas를 활용한 DataFrame 형성
Pandas 환경에서 Dictionary 자료 구조를 DataFrame을 변경하는 메소는 pd.DataFrame.from_dict( Dictionary Data )를 활용하면 아래의 사진과 같이 한 번에 정리할 수 있다. 다만 여기서 주의해야 할 것은 Dictionary 내 모든 요소가 길이가 같아야 형성할 수 있다.
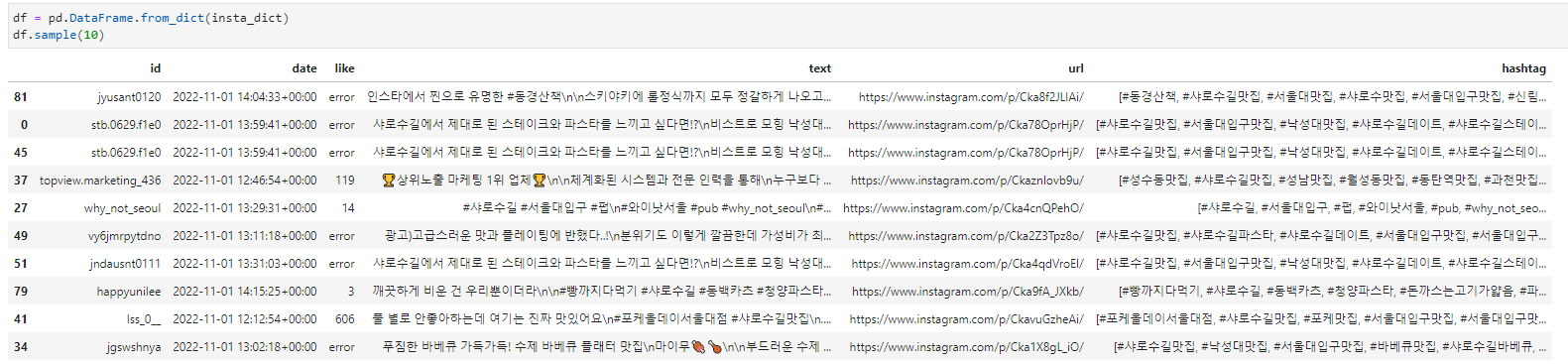
이렇게 되면 모든 데이터 수집은 완료되게 된다. 그대들의 과제에 성과가 있기를 바란다.