반응형
Bigquery나 Oracle 환경에서 Column 내에서 N번째 값이 조회해야 할 경우가 있다. 물론 첫 번째나 마지막 값이면 다소 쉬울 수 있겠지만 그 순서가 2번째나 3번째만 되어도 체감 난이도가 올라간다. 따라서 빅쿼리 탐색함수를 소개하여 이러한 문제를 어떻게 하면 쉽게 해결할 수 있을지 방법을 소개하고자 한다.
목차
1. 빅쿼리 탐색 함수 소개
2. 빅쿼리 FIRST_VALUE 함수 소개
3. 빅쿼리 LAST_VALUE 함수 소개
4. 빅쿼리 NTH_VALUE 함수 소개
1. Bigquery 탐색 함수 소개
- 탐색함수 종류 소개
- FIRST_VALUE: 원하는 기준에서 가장 첫 번째 값을 가져오는 함수
- LAST_VALUE: 원하는 기준에서 가장 마지막 값을 반환하는 함수
- NTH_VALUE: 원하는 기준에서 n번째 값을 반환하는 함수
- 탐색 함수 가이드
- 탐색함수(원하는Column) OVER (PARTITION BY 분리 기준 ORDER BY 정렬순서 )
- 원하는 Column: 데이터를 조회할 때, 조회하고 싶은 column을 넣으면 된다.
- 분리기준: 데이터 내 기준 혹은 집단에 따라 순서를 가져올 수 있다. 이 값은 선택적으로 넣어도 되고 안 넣어도 상관은 없는 영역이다.
- 정렬순서: 오름차순은 ASC이고 내림차순은 DESC이니, 원하는 기준에 맞게 사용하면 된다. 이 값은 반드시 정의해주어야 하는 영역이다.
- 탐색함수(원하는Column) OVER (PARTITION BY 분리 기준 ORDER BY 정렬순서 )
- 예시 데이터 셋 소개
함수 소개를 하기에 앞서서 이번에 사용할 예시 데이터 셋을 소개하고자 한다. 이는 임의로 만든 코드이니,
코드 연습을 할 때는 아래의 실습 예시코드를 복사 붙여넣기 해서 편하게 사용하기를 바란다. 예시를 짜는게 중요 Point가 아니기 때문에 굳이 힘을 뺄 필요가 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
WITH property_rank AS
(
SELECT 'Peter' as name, 1239 as asset_size, 'CAL' as region
UNION ALL SELECT 'Paul', 213289, 'NY'
UNION ALL SELECT 'Marry', 102930, 'CAL'
UNION ALL SELECT 'Michael', 39482498, 'NY'
UNION ALL SELECT 'Alex', 319283, 'CAL'
UNION ALL SELECT 'Victoria', 950433, 'NY'
UNION ALL SELECT 'Jane', 4981273, 'CAL'
UNION ALL SELECT 'Jamie', 209384, 'NY'
UNION ALL SELECT 'Carter', 39842, 'CAL'
UNION ALL SELECT 'Dora', 29034, 'NY'
UNION ALL SELECT 'John', 48923, 'CAL'
)
|
cs |
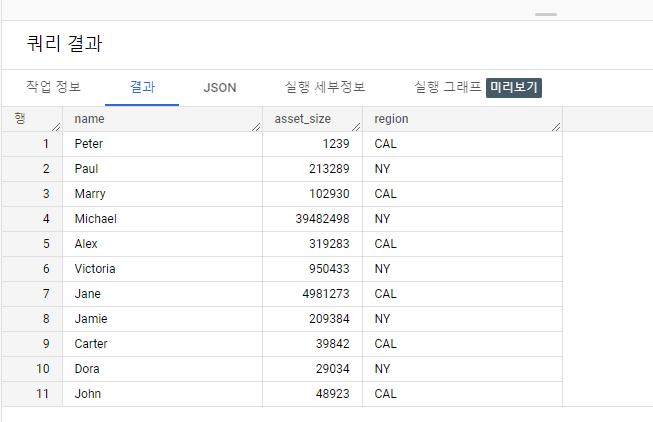
2. 빅쿼리 FIRST_VALUE 예시
- FIRST_VALUE 탐색 함수를 활용한 데이터 분석
- 분석 Question. CAL지역에서 자산순위가 가장 높은 사람은 누구이며, 사람들과 얼마나 차이가 나는가?
- 데이터 분석 결과 요약
- CAL 지역에서는 Jane이 가장 부자이며 자산 규모는 4,891,273이다.
- 사람들은 Jane과 4,661,990 ~ 4,980,034 정도 자산 차이가 나는 것으로 나타났다.
- 코드 논리 설명
- 분석의 핵심은 자산 규모였기 때문에 원하는 column은 t1.asset_size로 선정하였다.
- PARTITION BY의 기준은 지역별 자산 규모 비교 였기 때문에 t1.region Column을 선정하였다.
- 정렬순서는 가장 큰 사람이 먼저 와야 했기 때문에 DESC 코드 논리를 구성하였다.
|
1
2
3
4
5
6
7
|
## First Value함수를 통한 데이터
select t1.name
, t1.region
, t1.asset_size
, FIRST_VALUE(t1.asset_size) OVER (PARTITION BY t1.region ORDER BY t1.asset_size desc) as biggest_asset
, t1.asset_size - FIRST_VALUE(t1.asset_size) OVER (PARTITION BY t1.region ORDER BY t1.asset_size desc) as diff
from property_rank as t1
|
cs |
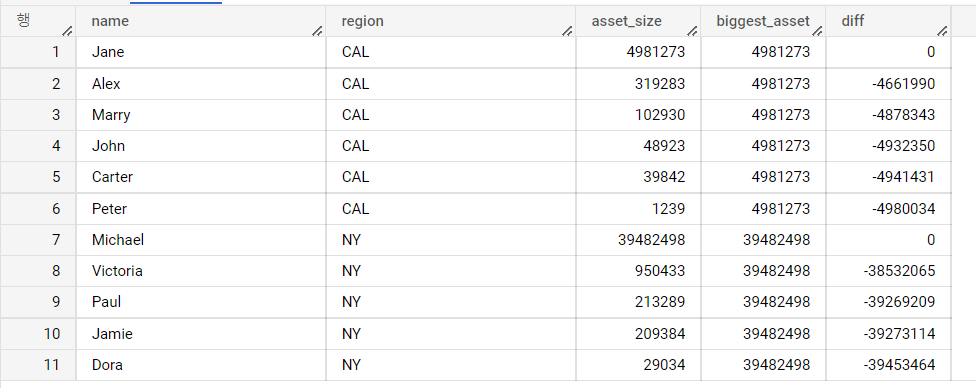
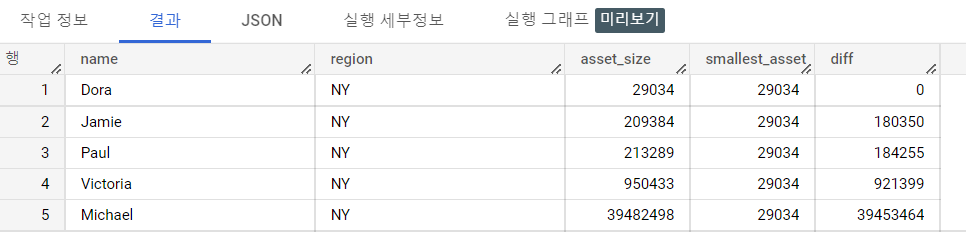
3. 빅쿼리 LAST_VALUE 함수 소개
- LAST_VALUE 탐색 함수를 활용한 데이터 분석
- 분석 Question. NY지역에서 자산순위가 가장 낮은 사람은 누구이며, 사람들과 얼마나 차이가 나는가?
- 데이터 분석 결과 요약
- NY 지역에서는 Jane이 가장 부자이며 자산 규모는 4,891,273이다.
- 사람들은 Jane과 4,661,990 ~ 4,980,034 정도 자산 차이가 나는 것으로 나타났다.
- 코드 논리 설명
- 분석의 핵심은 자산 규모였기 때문에 원하는 column은 t1.asset_size로 선정하였다.
- PARTITION BY의 기준은 지역별 자산 규모 비교 였기 때문에 t1.region Column을 선정하였다.
- 정렬순서는 가장 큰 사람이 먼저 와야 했기 때문에 DESC 코드 논리를 구성하였다.
- 또한 정렬의 기준이 row 단위로 독립적이여야 하기에 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING를 작성하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
select t1.name
, t1.region
, t1.asset_size
, LAST_VALUE(t1.asset_size) OVER
(PARTITION BY t1.region
ORDER BY t1.asset_size DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) as smallest_asset
from property_rank as t1
where 1 = 1
and t1.region = 'NY'
order by 3 asc
|
cs |
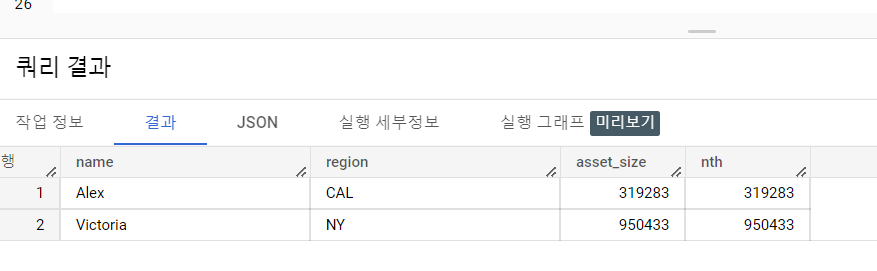
4. 빅쿼리 NTH_VALUE 함수 소개
- LAST_VALUE 탐색 함수를 활용한 데이터 분석
- 분석 Question. 지역별로 2번째로 자산이 많은 사람은 누구이고, 얼마나 가졌나
- 데이터 분석 결과 요약
- NY지역에서는 Victoria가 950,433이었고, CAL 지역에서는 Alex가 319,283으로 나타났다.
- 코드 논리 설명
- NTH_VALUE 함수를 사용할 때는 항상, NTH_VALUE(column, 원하는 순서)로 파라미터가 하나 추가되니 항상 기억하고 사용해야 한다.
- 이번에는 한명만 호출하는 것이 분석의 핵심이었기 때문에 subquery를 활용하여 원하는 row만 나오도록 설정하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
select df.*
from (
select a.name
, a.region
, a.asset_size
, nth_value(a.asset_size, 2) OVER (PARTITION BY a.region order by a.asset_size desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as nth
from property_rank as a
) as df
where 1 = 1
and df.asset_size = df.nth
|
cs |
반응형
'SQL - Mysql & Oracle > SQL 실무에 적용하기' 카테고리의 다른 글
| [빅쿼리] LEAD와 LAG로 이전값 이후값을 동시에 분석하기 (0) | 2022.11.10 |
|---|---|
| [Bigquery] SQL로 Loop과 While 반복문 제어하기(feat. 절차적 코드) (0) | 2022.10.26 |
| Python과 Bigquery 1분만에 연동하기 (0) | 2022.10.12 |
| [Bigquery] Big Query로 SQL 마스터 - 2. 공개 데이터셋 소개 (0) | 2022.06.14 |
| [Bigquery] Big Query로 SQL 마스터 - 1. 프로젝트 설정하기 (0) | 2022.06.11 |


